library(tidyverse)13 Analysis of variance
13.1 Movie ratings and lengths
Before a movie is shown in theatres, it receives a “rating” that says what kind of material it contains. link explains the categories, from G (suitable for children) to R (anyone under 17 must be accompanied by parent/guardian). In 2011, two students collected data on the length (in minutes) and the rating category, for 15 movies of each rating category, randomly chosen from all the movies released that year. The data are at link.
Read the data into R, and display (some of) what you read in.
Count how many movies there are of each rating.
Carry out an ANOVA and a Tukey analysis (if warranted).
Make a graph to assess whether this ANOVA is trustworthy. Discuss your graph and its implications briefly.
13.2 Deer and how much they eat
Do adult deer eat different amounts of food at different times of the year? The data in link are the weights of food (in kilograms) consumed by randomly selected adult deer observed at different times of the year (in February, May, August and November). We will assume that these were different deer observed in the different months. (If the same animals had been observed at different times, we would have been in the domain of “repeated measures”, which would require a different analysis, beyond the scope of this course.)
Read the data into R, and calculate numbers of observations and the median amounts of food eaten each month.
Make side-by-side boxplots of the amount of food eaten each month. Comment briefly on what you see.
Run a Mood’s median test as in lecture (ie. not using
smmr). What do you conclude, in the context of the data?Run a Mood’s median test using
smmr, and compare the results with the previous part.How is it that Mood’s median test does not completely answer the question you really want to answer? How might you get an answer to the question you really want answered? Explain briefly, and obtain the answer you really want, discussing your results briefly.
13.3 Movie ratings again
This question again uses the movie rating data at link.
Read the data into R and obtain the number of movies of each rating and the median length of movies of each rating.
Obtain a suitable graph that assesses the assumptions for ANOVA. Why do you think it is not reasonable to run ANOVA here? Explain briefly.
Run a Mood’s median test (use
smmrif you like). What do you conclude, in the context of the data?
13.4 Atomic weight of carbon
The atomic weight of the chemical element carbon is 12. Two methods of measuring the atomic weight of samples of carbon were compared. The results are shown in link. The methods are labelled 1 and 2. The first task is to find out whether the two methods have different “typical” measures (mean or median, as appropriate) of the atomic weight of carbon.
For this question, compose a report in a Quarto document. See part (a) for how to get this started.
Your report should read like an actual report, not just the answers to some questions that I set you. To help with that, write some text that links the parts of the report together smoothly, so that it reads as a coherent whole. The grader had 3 discretionary marks to award for the overall quality of your writing. The scale for this was:
3 points: excellent writing. The report flows smoothly, is easy to read, and contains everything it should (and nothing it shouldn’t).
2 points: satisfactory writing. Not the easiest to read, but says what it should, and it looks at least somewhat like a report rather than a string of answers to questions.
1 point: writing that is hard to read or to understand. If you get this (or 0), you should consider what you need to do to improve when you write your project.
0 points: you answered the questions, but you did almost nothing to make it read like a report.
Create a new Quarto document. To do this, in R Studio, select File, New File, Quarto Document. Type the report title and your name in the boxes, and leave the output on the default HTML. Click OK.
Write an introduction that explains the purpose of this study and the data collected in your own words.
Begin an appropriately-titled new section in your report, read the data into R and display the results.
Make an appropriate plot to compare the measurements obtained by the two methods. You might need to do something about the two methods being given as numbers even though they are really only identifiers. (If you do, your report ought to say what you did and why.)
Comment briefly on what you see in your plot.
Carry out the most appropriate \(t\)-test. (You might like to begin another new section in your report here.)
Do the most appropriate test you know that does not assume normally-distributed data.
Discuss the results of your tests and what they say about the two methods for measuring the atomic weight of carbon. If it seems appropriate, put the discussion into a section called Conclusions.
13.5 Can caffeine improve your performance on a test?
Does caffeine help students do better on a certain test? To find out, 36 students were randomly allocated to three groups (12 in each group). Each student received a fixed number of cups of coffee while they were studying, but the students didn’t know whether they were receiving all full-strength coffee (“high”), all decaf coffee (“low”) or a 50-50 mixture of the two (“moderate”). For each subject, their group was recorded as well as their score on the test. The data are in link, as a .csv file.
Read in and examine the data. How are the values laid out?
Explain briefly how the data are not “tidy”.
Use a suitable tool from the
tidyverseto create one column of test scores and and one column of group labels. Call your column of group labelsamount. Is it afactor?Obtain side-by-side boxplots of test scores by amount of caffeine.
Does caffeine amount seem to have an effect? If so, what kind of effect?
Run a suitable analysis of variance to determine whether the mean test score is equal or unequal for the three groups. What do you conclude?
Why is it a good idea to run Tukey’s method here?
Run Tukey’s method. What do you conclude?
13.6 Reggae music
Reggae is a music genre that originated in Jamaica in the late 1960s. One of the most famous reggae bands was Bob Marley and the Wailers. In a survey, 729 students were asked to rate reggae music on a scale from 1, “don’t like it at all” to 6, “like it a lot”. We will treat the ratings as quantitative. Each student was also asked to classify their home town as one of “big city”, “suburban”, “small town”, “rural”. Does a student’s opinion of reggae depend on the kind of home town they come from? The data are in http://ritsokiguess.site/datafiles/reggae.csv.
Read in and display (some of) the data.
How many students are from each different size of town?
Make a suitable graph of the two variables in this data frame.
Discuss briefly why you might prefer to run Mood’s median test to compare ratings among home towns.
Suppose that somebody wanted to run Welch ANOVA on these data. What would be a reasonable argument to support that?
Run Mood’s median test and display the output.
Explain briefly why running pairwise median tests is a good idea, run them, and display the results.
Summarize, as concisely as possible, how the home towns differ in terms of their students’ ratings of reggae music.
13.7 Watching TV and education
The General Social Survey is a large survey of a large number of people. One of the questions on the survey is “how many hours of TV do you watch in a typical day?” Another is “what is your highest level of education attained”, on this scale:
- HSorLess: completed no more than high h school
- College: completed some form of college, either a community college (like Centennial) or a four-year university (like UTSC)
- Graduate: completed a graduate degree such as an MSc.
Do people with more education tend to watch more TV? We will be exploring this. The data are in http://ritsokiguess.site/datafiles/gss_tv.csv.
Read in and display (some of) the data.
For each level of education, obtain the number of observations, the mean and the median of the number of hours of TV watched.
What does your answer to the previous part tell you about the shapes of the distributions of the numbers of hours of TV watched? Explain briefly.
Obtain a suitable graph of your data frame.
Does your plot indicate that your guess about the distribution shape was correct? Explain briefly.
Run a suitable test to compare the average number of hours of TV watched for people with each amount of education. (“Average” could be mean or median, whichever you think is appropriate.)
What do you conclude from your test, in the context of the data?
Why might you now want to run some kind of follow-up test? Run the appropriate thing and explain briefly what you conclude from it, in the context of the data.
13.8 Death of poets
Some people believe that poets, especially female poets, die younger than other types of writer. William Butler Yeats1 wrote:
She is the Gaelic2 muse, for she gives inspiration to those she persecutes. The Gaelic poets die young, for she is restless, and will not let them remain long on earth.
A literature student wanted to investigate this, and so collected a sample of 123 female writers (of three different types), and noted the age at death of each writer.
The data are in http://ritsokiguess.site/datafiles/writers.csv.
Read in and display (some of) the data.
Make a suitable plot of the ages and types of writing.
Obtain a summary table showing, for each type of writing, the number of writers of that type, along with the mean, median and standard deviation of their ages at death.
Run a complete analysis, starting with an ordinary (not Welch) analysis of variance, that ends with a conclusion in the context of the data and an assessment of assumptions.
13.9 Religion and studying
Many students at a certain university were asked about the importance of religion in their lives (categorized as “not”, “fairly”, or “very” important), and also about the number of hours they spent studying per week. (This was part of a much larger survey.) We want to see whether there is any kind of relationship between these two variables. The data are in here.
Read in and display (some of) the data.
Obtain the number of observations and the mean and standard deviation of study hours for each level of importance.
Comment briefly on how the groups compare in terms of study hours.
Make a suitable graph of this data set.
The statistician in this study decided that the data were sufficiently normal in shape given the (very large) sample sizes, but was concerned about unequal spreads among the three groups. Given this, run a suitable analysis and display the output. (This includes a suitable follow-up test, if warranted.)
What do you conclude from your analysis of the previous part, in the context of the data?
My solutions follow:
13.10 Movie ratings and lengths
Before a movie is shown in theatres, it receives a “rating” that says what kind of material it contains. link explains the categories, from G (suitable for children) to R (anyone under 17 must be accompanied by parent/guardian). In 2011, two students collected data on the length (in minutes) and the rating category, for 15 movies of each rating category, randomly chosen from all the movies released that year. The data are at link.
- Read the data into R, and display (some of) what you read in.
Solution
read_csv:
my_url <- "http://ritsokiguess.site/datafiles/movie-lengths.csv"
movies <- read_csv(my_url)Rows: 60 Columns: 2
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (1): rating
dbl (1): length
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.moviesSomething that looks like a length in minutes, and a rating.
\(\blacksquare\)
- Count how many movies there are of each rating.
Solution
movies %>% count(rating)Fifteen of each rating. (It’s common to have the same number of observations in each group, but not necessary for a one-way ANOVA.)
\(\blacksquare\)
- Carry out an ANOVA and a Tukey analysis (if warranted).
Solution
ANOVA first:
length.1 <- aov(length ~ rating, data = movies)
summary(length.1) Df Sum Sq Mean Sq F value Pr(>F)
rating 3 14624 4875 11.72 4.59e-06 ***
Residuals 56 23295 416
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1This P-value is 0.00000459, which is way less than 0.05.
Having rejected the null (which said “all means equal”), we now need to do Tukey, thus:
TukeyHSD(length.1) Tukey multiple comparisons of means
95% family-wise confidence level
Fit: aov(formula = length ~ rating, data = movies)
$rating
diff lwr upr p adj
PG-G 26.333333 6.613562 46.053104 0.0044541
PG-13-G 42.800000 23.080229 62.519771 0.0000023
R-G 30.600000 10.880229 50.319771 0.0007379
PG-13-PG 16.466667 -3.253104 36.186438 0.1327466
R-PG 4.266667 -15.453104 23.986438 0.9397550
R-PG-13 -12.200000 -31.919771 7.519771 0.3660019Cast your eye down the p adj column and look for the ones that are significant, here the first three. These are all comparisons with the G (“general”) movies, which are shorter on average than the others (which are not significantly different from each other).
If you like, you can make a table of means to verify that:
movies %>%
group_by(rating) %>%
summarize(mean = mean(length))\(\blacksquare\)
- Make a graph to assess whether this ANOVA is trustworthy. Discuss your graph and its implications briefly.
Solution
The obvious graph is a boxplot:
ggplot(movies, aes(x = rating, y = length)) + geom_boxplot()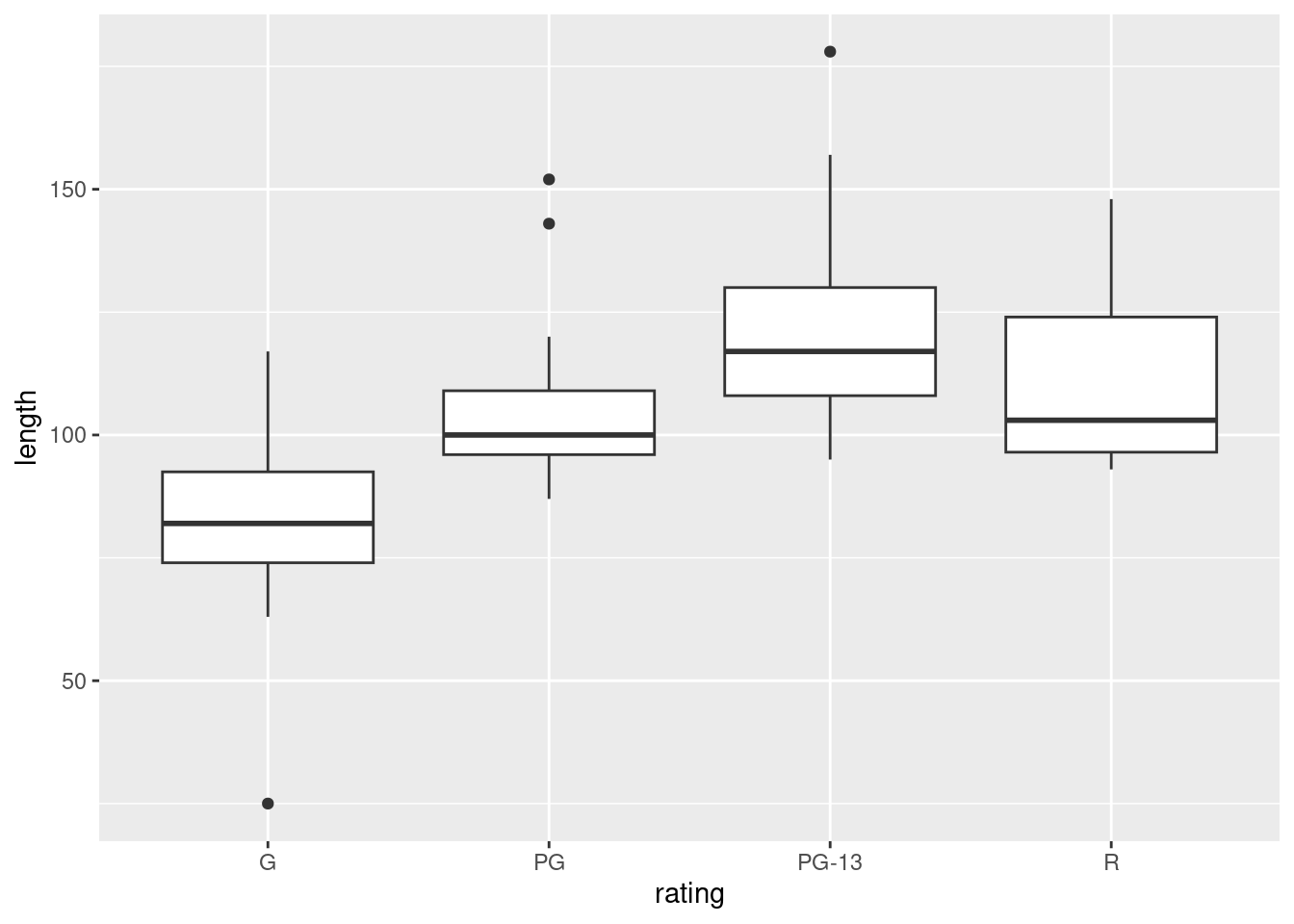
For ANOVA, we are looking for approximately normal distributions within each group and approximately equal spreads. Without the outliers, I would be more or less happy with that, but the G movies have a low outlier that would pull the mean down and the PG and PG-13 movies have outliers that would pull the mean up. So a comparison of means might make the differences look more significant than they should. Having said that, you could also say that the ANOVA is very significant, so even considering the effect of the outliers, the differences between G and the others are still likely to be significant.
Extra: the way to go if you don’t trust the ANOVA is (as for the two-sample \(t\)) the Mood’s median test. This applies to any number of groups, and works in the same way as before:
library(smmr)
median_test(movies, length, rating)$grand_median
[1] 100
$table
above
group above below
G 2 13
PG 7 7
PG-13 12 3
R 8 6
$test
what value
1 statistic 13.752380952
2 df 3.000000000
3 P-value 0.003262334Still significant, though not quite as small a P-value as before (which echoes our thoughts about what the outliers might do to the means). If you look at the table above the test results, you see that the G movies are mostly shorter than the overall median, but now the PG-13 movies are mostly longer. So the picture is a little different.
Mood’s median test does not naturally come with something like Tukey. What you can do is to do all the pairwise Mood’s median tests, between each pair of groups, and then adjust to allow for your having done several tests at once. I thought this was generally useful enough that I put it into smmr under the name pairwise_median_test:
pairwise_median_test(movies, length, rating)You can ignore those (adjusted) P-values rather stupidly bigger than 1. These are not significant.
There are two significant differences in median length: between G movies and the two flavours of PG movies. The G movies are significantly shorter (as you can tell from the boxplot), but the difference between G and R movies is no longer significant (a change from the regular ANOVA).
You may be puzzled by something in the boxplot: how is it that the G movies are significantly shorter than the PG movies, but not significantly shorter than the R movies, when the difference in medians between G and R movies is bigger? In Tukey, if the difference in means is bigger, the P-value is smaller.3 The resolution to this puzzle, such as it is, is that Mood’s median test is not directly comparing the medians of the groups (despite its name); it’s counting values above and below a joint median, which might be a different story.
\(\blacksquare\)
13.11 Deer and how much they eat
Do adult deer eat different amounts of food at different times of the year? The data in link are the weights of food (in kilograms) consumed by randomly selected adult deer observed at different times of the year (in February, May, August and November). We will assume that these were different deer observed in the different months. (If the same animals had been observed at different times, we would have been in the domain of “repeated measures”, which would require a different analysis, beyond the scope of this course.)
- Read the data into R, and calculate numbers of observations and the median amounts of food eaten each month.
Solution
The usual stuff for data values separated by (single) spaces:
myurl <- "http://ritsokiguess.site/datafiles/deer.txt"
deer <- read_delim(myurl, " ")Rows: 22 Columns: 2
── Column specification ────────────────────────────────────────────────────────
Delimiter: " "
chr (1): month
dbl (1): food
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.and then, recalling that n() is the handy way of getting the number of observations in each group:
deer %>%
group_by(month) %>%
summarize(n = n(), med = median(food))When you want the number of observations plus some other summaries, as here, the group-by and summarize idea is the way, using n() to get the number of observations in each group. count counts the number of observations per group when you only have grouping variables.
The medians differ a bit, but it’s hard to judge without a sense of spread, which the boxplots (next) provide. November is a bit higher and May a bit lower.
\(\blacksquare\)
- Make side-by-side boxplots of the amount of food eaten each month. Comment briefly on what you see.
Solution
ggplot(deer, aes(x = month, y = food)) + geom_boxplot()
This offers the suggestion that maybe November will be significantly higher than the rest and May significantly lower, or at least they will be significantly different from each other.
This is perhaps getting ahead of the game: we should be thinking about spread and shape. Bear in mind that there are only 5 or 6 observations in each group, so you won’t be able to say much about normality. In any case, we are going to be doing a Mood’s median test, so any lack of normality doesn’t matter (eg. perhaps that 4.4 observation in August). Given the small sample sizes, I actually think the spreads are quite similar.
Another way of looking at the data, especially with these small sample sizes, is a “dot plot”: instead of making a boxplot for each month, we plot the actual points for each month as if we were making a scatterplot:
ggplot(deer, aes(x = month, y = food)) + geom_point()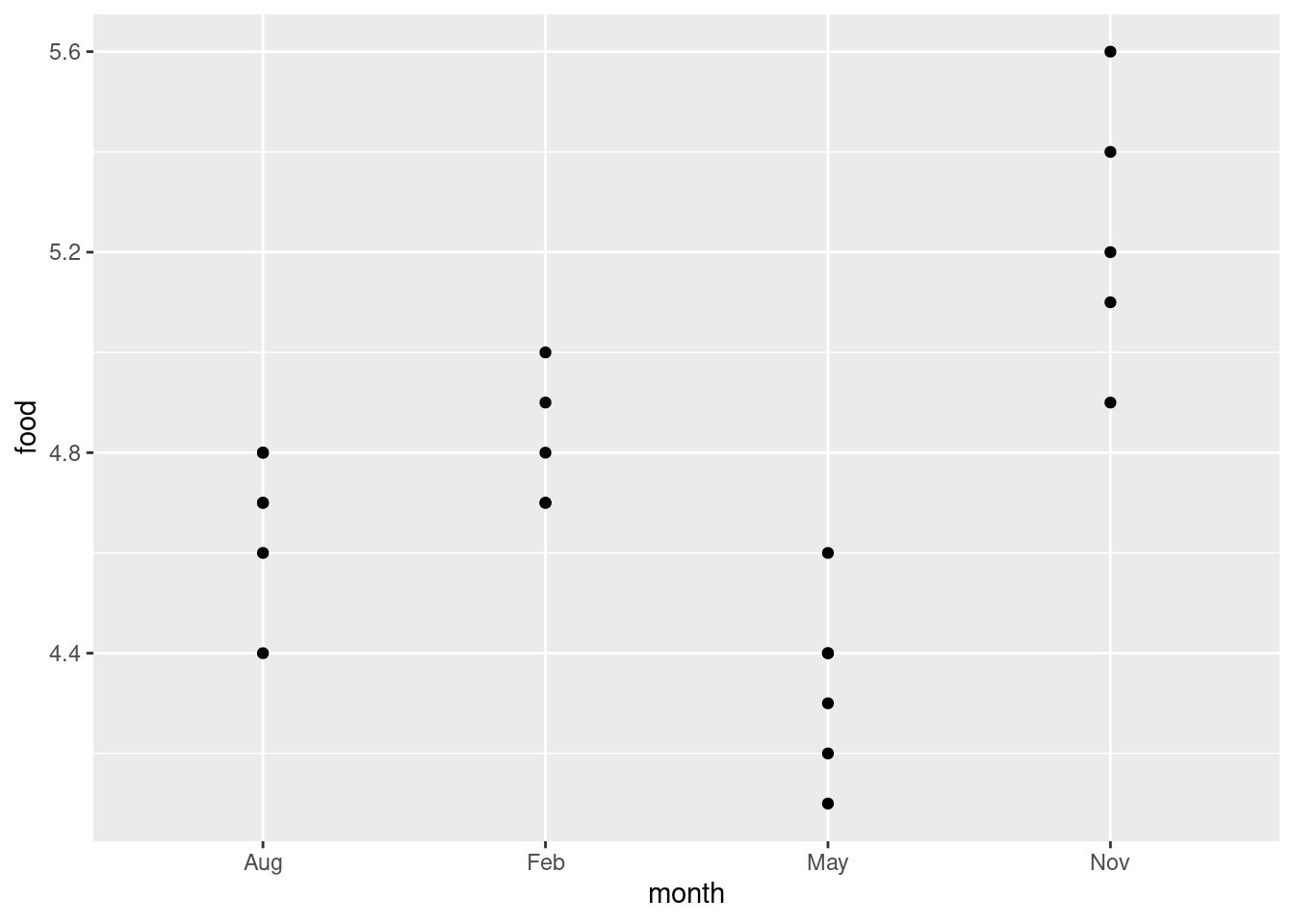
Wait a minute. There were five deer in February and six in August. Where did they go?
The problem is overplotting: more than one of the deer plotted in the same place on the plot, because the amounts of food eaten were only given to one decimal place and there were some duplicated values. One way to solve this is to randomly move the points around so that no two of them plot in the same place. This is called jittering, and is done like this:
ggplot(deer, aes(x = month, y = food)) + geom_jitter(width = 0, height = 0.05)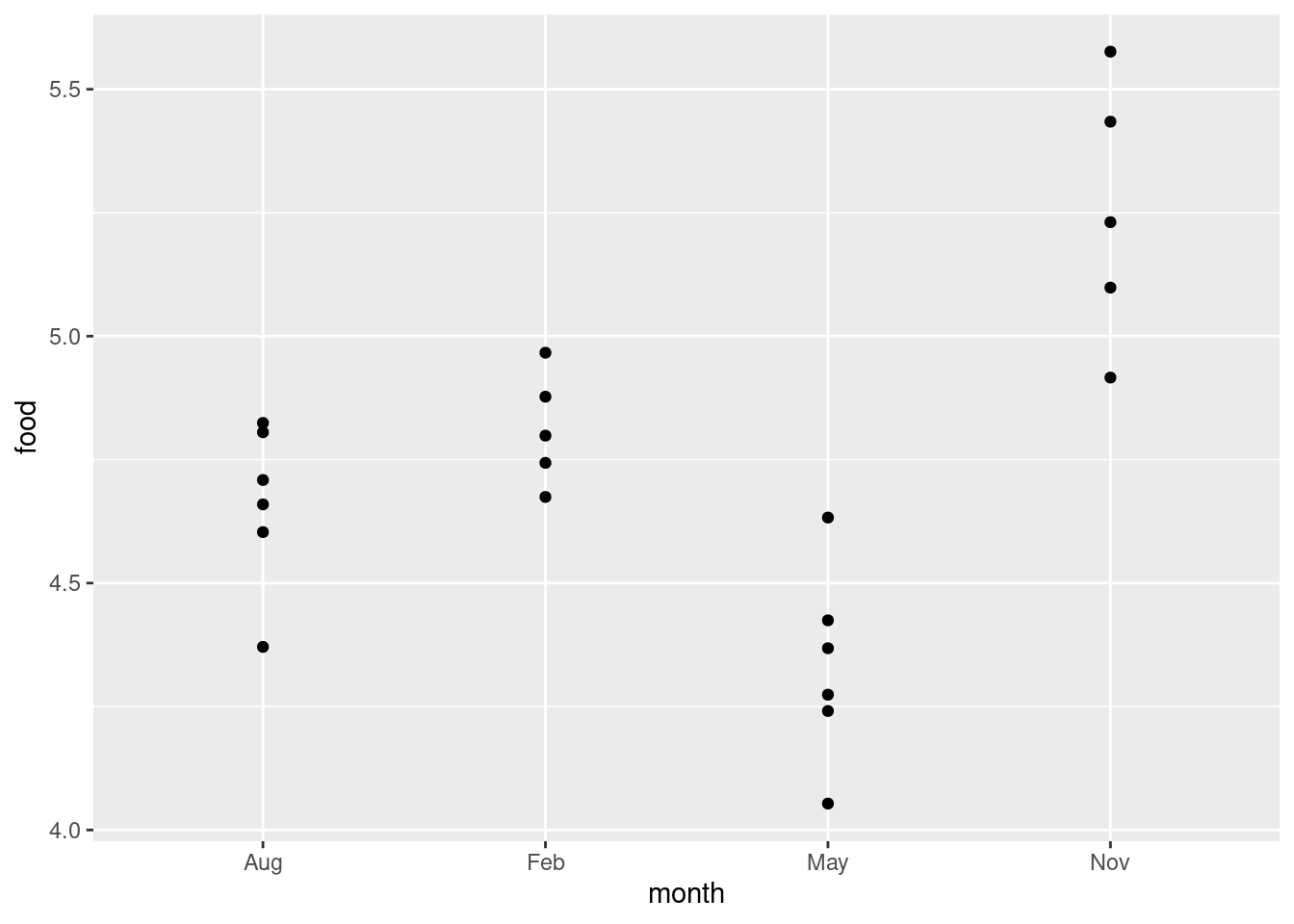
Now you see all the deer, and you can see that two pairs of points in August and one pair of points in February are close enough on the jittered plot that they would have been the same to one decimal place.
I wanted to keep the points above the months they belong to, so I only allowed vertical jitter (that’s the width and height in the geom_jitter; the width is zero so there is no horizontal jittering). If you like, you can colour the months; it’s up to you whether you think that’s making the plot easier to read, or is overkill (see my point on the facetted plots on the 2017 midterm).
This way you see the whole distribution for each month. Normally it’s nicer to see the summary made by the boxplots, but here there are not very many points. The value of 4.4 in August does look quite a bit lower than the rest, but the other months look believably normal given the small sample sizes. I don’t know about equal spreads (November looks more spread out), but normality looks believable. Maybe this is the kind of situation in which Welch’s ANOVA is a good idea. (If you believe that the normality-with-unequal-spreads is a reasonable assumption to make, then the Welch ANOVA will be more powerful than the Mood’s median test, and so should be preferred.)
\(\blacksquare\)
- Run a Mood’s median test as in lecture (ie. not using
smmr). What do you conclude, in the context of the data?
Solution
To give you some practice with the mechanics, first find the overall median:
deer %>% summarize(med = median(food))or
median(deer$food)[1] 4.7I like the first way because it’s the same idea as we did before, just not differentiating by month. I think there are some observations exactly equal to the median, which will mess things up later:
deer %>% filter(food == 4.7)There are, two in February and two in August.
Next, make (and save) a table of the observations within each month that are above and below this median:
tab1 <- with(deer, table(month, food < 4.7))
tab1
month FALSE TRUE
Aug 4 2
Feb 5 0
May 0 6
Nov 5 0or
tab2 <- with(deer, table(month, food > 4.7))
tab2
month FALSE TRUE
Aug 4 2
Feb 2 3
May 6 0
Nov 0 5Either of these is good, but note that they are different. Two of the February observations (the ones that were exactly 4.7) have “switched sides”, and (look carefully) two of the August ones also. Hence the test results will be different, and smmr (later) will give different results again:
chisq.test(tab1, correct = F)Warning in chisq.test(tab1, correct = F): Chi-squared approximation may be
incorrect
Pearson's Chi-squared test
data: tab1
X-squared = 16.238, df = 3, p-value = 0.001013chisq.test(tab2, correct = F)Warning in chisq.test(tab2, correct = F): Chi-squared approximation may be
incorrect
Pearson's Chi-squared test
data: tab2
X-squared = 11.782, df = 3, p-value = 0.008168The warnings are because of the small frequencies. If you’ve done these by hand before (which you will have if you took PSYC08), you’ll remember that thing about “expected frequencies less than 5”. This is that. It means “don’t take those P-values too seriously.”
The P-values are different, but they are both clearly significant, so the median amounts of food eaten in the different months are not all the same. (This is the same “there are differences” that you get from an ANOVA, which you would follow up with Tukey.) Despite the injunction not to take the P-values too seriously, I think these are small enough that they could be off by a bit without affecting the conclusion.
The first table came out with a smaller P-value because it looked more extreme: all of the February measurements were taken as higher than the overall median (since we were counting “strictly less” and “the rest”). In the second table, the February measurements look more evenly split, so the overall P-value is not quite so small.
You can make a guess as to what smmr will come out with (next), since it throws away any data values exactly equal to the median.
\(\blacksquare\)
- Run a Mood’s median test using
smmr, and compare the results with the previous part.
Solution
Off we go:
library(smmr)
median_test(deer, food, month)$grand_median
[1] 4.7
$table
above
group above below
Aug 2 2
Feb 3 0
May 0 6
Nov 5 0
$test
what value
1 statistic 13.950000000
2 df 3.000000000
3 P-value 0.002974007The P-value came out in between the other two, but the conclusion is the same all three ways: the months are not all the same in terms of median food eaten. The researchers can then go ahead and try to figure out why the animals eat different amounts in the different months.
You might be wondering how you could get rid of the equal-to-median values in the build-it-yourself way. This is filter from dplyr, which you use first:
deer2 <- deer %>% filter(food != 4.7)
tab3 <- with(deer2, table(month, food < 4.7))
tab3
month FALSE TRUE
Aug 2 2
Feb 3 0
May 0 6
Nov 5 0chisq.test(tab3)Warning in chisq.test(tab3): Chi-squared approximation may be incorrect
Pearson's Chi-squared test
data: tab3
X-squared = 13.95, df = 3, p-value = 0.002974which is exactly what smmr does, so the answer is identical.4 How would an ANOVA come out here? My guess is, very similarly:
deer.1 <- aov(food ~ month, data = deer)
summary(deer.1) Df Sum Sq Mean Sq F value Pr(>F)
month 3 2.3065 0.7688 22.08 2.94e-06 ***
Residuals 18 0.6267 0.0348
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1TukeyHSD(deer.1) Tukey multiple comparisons of means
95% family-wise confidence level
Fit: aov(formula = food ~ month, data = deer)
$month
diff lwr upr p adj
Feb-Aug 0.1533333 -0.16599282 0.4726595 0.5405724
May-Aug -0.3333333 -0.63779887 -0.0288678 0.0290758
Nov-Aug 0.5733333 0.25400718 0.8926595 0.0004209
May-Feb -0.4866667 -0.80599282 -0.1673405 0.0021859
Nov-Feb 0.4200000 0.08647471 0.7535253 0.0109631
Nov-May 0.9066667 0.58734052 1.2259928 0.0000013The conclusion is the same, but the P-value on the \(F\)-test is much smaller. I think this is because the \(F\)-test uses the actual values, rather than just whether they are bigger or smaller than 4.7. The Tukey says that all the months are different in terms of (now) mean, except for February and August, which were those two very similar ones on the boxplot.
\(\blacksquare\)
- How is it that Mood’s median test does not completely answer the question you really want to answer? How might you get an answer to the question you really want answered? Explain briefly, and obtain the answer you really want, discussing your results briefly.
Solution
That’s rather a lot, so let’s take those things one at a time.5
Mood’s median test is really like the \(F\)-test in ANOVA: it’s testing the null hypothesis that the groups (months) all have the same median (of food eaten), against the alternative that the null is not true. We rejected this null, but we don’t know which months differ significantly from which. To resolve this in ANOVA, we do Tukey (or Games-Howell if we did the Welch ANOVA). The corresponding thing here is to do all the possible two-group Mood tests on all the pairs of groups, and, after adjusting for doing (here) six tests at once, look at the adjusted P-values to see how the months differ in terms of food eaten.
This is accomplished in smmr via pairwise_median_test, thus:
pairwise_median_test(deer, food, month)This compares each month with each other month. Looking at the last column, there are only three significant differences: August-November, February-May and May-November. Going back to the table of medians we made in (a), November is significantly higher (in terms of median food eaten) than August and May (but not February), and February is significantly higher than May. The other differences are not big enough to be significant.
Extra: Pairwise median tests done this way are not likely to be very sensitive (that is, powerful), for a couple of reasons: (i) the usual one that the median tests don’t use the data very efficiently, and (ii) the way I go from the unadjusted to the adjusted P-values is via Bonferroni (here, multiply the P-values by 6), which is known to be safe but conservative. This is why the Tukey produced more significant differences among the months than the pairwise median tests did.
\(\blacksquare\)
13.12 Movie ratings again
This question again uses the movie rating data at link.
- Read the data into R and obtain the number of movies of each rating and the median length of movies of each rating.
Solution
Reading in is as in the other question using these data (just copy your code, or mine).
my_url <- "http://ritsokiguess.site/datafiles/movie-lengths.csv"
movies <- read_csv(my_url)Rows: 60 Columns: 2
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (1): rating
dbl (1): length
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.moviesNow, the actual for-credit part, which is a group_by and summarize:
movies %>%
group_by(rating) %>%
summarize(count = n(), med = median(length))The G movies have a smaller median than the others, but also the PG-13 movies seem to be longer on average (not what we found before).
\(\blacksquare\)
- Obtain a suitable graph that assesses the assumptions for ANOVA. Why do you think it is not reasonable to run ANOVA here? Explain briefly.
Solution
The graph would seem to be a boxplot, side by side for each group:
ggplot(movies, aes(x = rating, y = length)) + geom_boxplot()
We are looking for approximate normal distributions with approximately equal spreads, which I don’t think we have: there are outliers, at the low end for G movies, and at the high end for PG and PG-13 movies. Also, you might observe that the distribution of lengths for R movies is skewed to the right. (Noting either the outliers or skewness as a reason for not believing normality is enough, since all we need is one way that normality fails.)
I think the spreads (as measured by the interquartile ranges) are acceptably similar, but since we have rejected normality, it is a bit late for that.
So I think it is far from reasonable to run an ANOVA here. In my opinion 15 observations in each group is not enough to gain much from the Central Limit Theorem either.
Extra: since part of the assumption for ANOVA is (approximate) normality, it would also be entirely reasonable to make normal quantile plots, one for each movie type, facetted. Remember the process: you pretend that you are making a normal quantile plot for all the data together, regardless of group, and then at the last minute, you throw in a facet_wrap. I’ve written the code out on three lines, so that you can see the pieces: the “what to plot”, then the normal quantile plot part, then the facetting:
ggplot(movies, aes(sample = length)) +
stat_qq() + stat_qq_line() +
facet_wrap(~rating)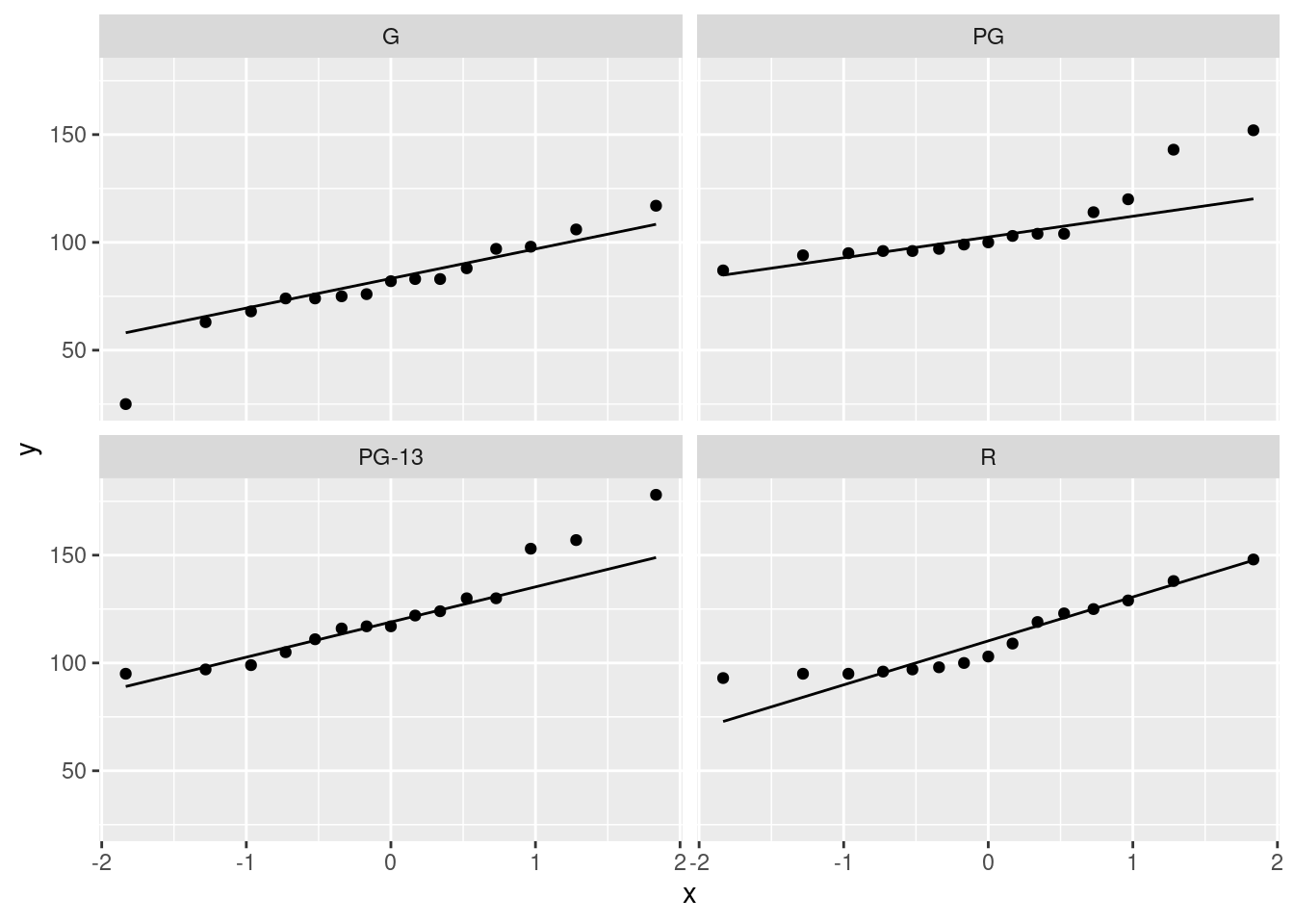
Since there are four movie ratings, facet_wrap has arranged them into a \(2\times 2\) grid, which satisfyingly means that each normal quantile plot is more or less square and thus easy to interpret.
The principal problem unveiled by these plots is outliers. It looks as if the G movies have one low outlier, the PG movies have two high outliers, the PG-13 movies have one or maybe three high outliers (depending on how you count them), and the R movies have none. Another way to look at the last two is you could call them curved, with too much bunching up at the bottom and (on PG-13) too much spread-out-ness at the top, indicating right-skewed distributions. The distribution of lengths of the R-rated movies is too bunched up at the bottom, but as you would expect for a normal at the top. The R movies show the right-skewedness in an odd way: usually this skewness shows up by having too many high values, but this time it’s having too few low values.
The assumption for ANOVA is that all four of these are at least approximately normal (with the same spread). We found problems with the normality on at least three of them, so we definitely have doubts about trusting ANOVA here.
I could have used scales=free here to get a separate \(y\)-axis for each plot, but since the \(y\)-axis is movie length each time, and all four groups would be expected to have at least roughly similar movie lengths, I left it as it was. (The other advantage of leaving the scales the same is that you can compare spread by comparing the slopes of the lines on these graphs; since the lines connect the observed and theoretical quartiles, a steeper slope means a larger IQR. Here, the R line is steepest and the PG line is flattest. Compare this with the spreads of the boxplots.)
Extra extra: if you want, you can compare the normal quantile plots with the boxplots to see whether you get the same conclusion from both. For the G movies, the low outlier shows up both ways, and the rest of the distribution is at least more or less normal. For the PG movies, I’d say the distribution is basically normal except for the highest two values (on both plots). For the PG-13 movies, only the highest value shows up as an outlier, but the next two apparent outliers on the normal quantile plot are at the upper end of the long upper whisker, so the boxplot is saying “right-skewed with one upper outlier” rather than “three upper outliers”. The distribution of the R movies is skewed right, with the bunching at the bottom showing up as the very small lower whisker.
The boxplots and the normal quantile plots are basically telling the same story in each case, but they are doing it in a slightly different way.
\(\blacksquare\)
- Run a Mood’s median test (use
smmrif you like). What do you conclude, in the context of the data?
Solution
The smart way is to use smmr, since it is much easier:
library(smmr)
median_test(movies, length, rating)$grand_median
[1] 100
$table
above
group above below
G 2 13
PG 7 7
PG-13 12 3
R 8 6
$test
what value
1 statistic 13.752380952
2 df 3.000000000
3 P-value 0.003262334The movies do not all have the same median length, or at least one of the rating types has movies of different median length from the others. Or something equivalent to that. It’s the same conclusion as for ANOVA, only with medians instead of means.
You can speculate about why the test came out significant. My guess is that the G movies are shorter than average, and that the PG-13 movies are longer than average. (We had the first conclusion before, but not the second. This is where medians are different from means.)
The easiest way to see which movie types really differ in length from which is to do all the pairwise median tests, which is in smmr thus:
pairwise_median_test(movies, length, rating)The inputs for this are the same ones in the same order as for median_test. (A design decision on my part, since otherwise I would never have been able to remember how to run these!) Only the first two of these are significant (look in the last column). We can remind ourselves of the sample medians:
movies %>%
group_by(rating) %>%
summarize(count = n(), med = median(length))The G movies are significantly shorter than the PG and PG-13 movies, but not quite significantly different from the R movies. This is a little odd, since the difference in sample medians between G and PG, significant, is less than for G and R (not significant). There are several Extras here, which you can skip if you don’t care about the background. First, we can do the median test by hand: This has about four steps: (i) find the median of all the data, (ii) make a table tabulating the number of values above and below the overall median for each group, (iii) test the table for association, (iv) draw a conclusion. Thus (i):
median(movies$length)[1] 100or
movies %>% summarize(med = median(length))or store it in a variable, and then (ii):
tab1 <- with(movies, table(length < 100, rating))
tab1 rating
G PG PG-13 R
FALSE 2 8 12 9
TRUE 13 7 3 6or
tab2 <- with(movies, table(length > 100, rating))
tab2 rating
G PG PG-13 R
FALSE 13 8 3 7
TRUE 2 7 12 8These differ because there are evidently some movies of length exactly 100 minutes, and it matters whether you count \(<\) and \(\ge\) (as in tab1) or \(>\) and \(le\) (tab2). Either is good.
Was I right about movies of length exactly 100 minutes?
movies %>% filter(length == 100)One PG and one R. It makes a difference to the R movies, but if you look carefully, it makes a difference to the PG movies as well, because the False and True switch roles between tab1 and tab2 (compare the G movies, for instance). You need to store your table in a variable because it has to get passed on to chisq.test below, (iii):
chisq.test(tab1, correct = FALSE)
Pearson's Chi-squared test
data: tab1
X-squared = 14.082, df = 3, p-value = 0.002795or
chisq.test(tab2, correct = FALSE)
Pearson's Chi-squared test
data: tab2
X-squared = 13.548, df = 3, p-value = 0.003589Either is correct, or, actually, without the correct=FALSE.6
The conclusion (iv) is the same either way: the null of no association is clearly rejected (with a P-value of 0.0028 or 0.0036 as appropriate), and therefore whether a movie is longer or shorter than median length depends on what rating it has: that is, the median lengths do differ among the ratings. The same conclusion, in other words, as the \(F\)-test gave, though with not quite such a small P-value.
Second, you might be curious about how we might do something like Tukey having found some significant differences (that is, what’s lurking in the background of pairwise_median_test).
Let’s first suppose we are comparing G and PG movies. We need to pull out just those, and then compare them using smmr. Because the first input to median_test is a data frame, it fits neatly into a pipe (with the data frame omitted):
movies %>%
filter(rating == "G" | rating == "PG") %>%
median_test(length, rating)$grand_median
[1] 96
$table
above
group above below
G 4 11
PG 10 3
$test
what value
1 statistic 7.035897436
2 df 1.000000000
3 P-value 0.007989183We’re going to be doing this about six times — \({4 \choose 2}=6\) choices of two rating groups to compare out of the four — so we should have a function to do it. I think the input to the function should be a data frame that has a column called rating, and two names of ratings to compare:
comp2 <- function(rat_1, rat_2, d) {
d %>%
filter(rating == rat_1 | rating == rat_2) %>%
median_test(length, rating)
}The way I wrote this function is that you have to specify the movie ratings in quotes. It is possible to write it in such a way that you input them without quotes, tidyverse style, but that gets into “non-standard evaluation” and enquo() and !!, which (i) I have to look up every time I want to do it, and (ii) I am feeling that the effort involved in explaining it to you is going to exceed the benefit you will gain from it. I mastered it enough to make it work in smmr (note that you specify column names without quotes there). There are tutorials on this kind of thing if you’re interested.
Anyway, testing:
comp2("G", "PG", movies)$grand_median
[1] 96
$table
above
group above below
G 4 11
PG 10 3
$test
what value
1 statistic 7.035897436
2 df 1.000000000
3 P-value 0.007989183That works, but I really only want to pick out the P-value, which is in the list item test in the column value, the third entry. So let’s rewrite the function to return just that:
comp2 <- function(rat_1, rat_2, d) {
d %>%
filter(rating == rat_1 | rating == rat_2) %>%
median_test(length, rating) %>%
pluck("test", "value", 3)
}
comp2("G", "PG", movies)[1] 0.007989183Gosh.
What median_test returns is an R list that has two things in it, one called table and one called test. The thing called test is a data frame with a column called value that contains the P-values. The third of these is the two-sided P-value that we want.
You might not have seen pluck before. This is a way of getting things out of complicated data structures. This one takes the output from median_test and from it grabs the piece called test. This is a data frame. Next, we want the column called value, and from that we want the third row. These are specified one after the other to pluck and it pulls out the right thing.
So now our function returns just the P-value.
I have to say that it took me several goes and some playing around in R Studio to sort this one out. Once I thought I understood pluck, I wondered why my function was not returning a value. And then I realized that I was saving the value inside the function and not returning it. Ooops. The nice thing about pluck is that I can put it on the end of the pipeline and and it will pull out (and return) whatever I want it to.
Let’s grab a hold of the different rating groups we have:
the_ratings <- unique(movies$rating)
the_ratings[1] "G" "PG-13" "PG" "R" The Pythonisti among you will know how to finish this off: do a loop-inside-a-loop over the rating groups, and get the P-value for each pair. You can do that in R, if you must. It’s not pretty at all, but it works:
ii <- character(0)
jj <- character(0)
pp <- numeric(0)
for (i in the_ratings) {
for (j in the_ratings) {
pval <- comp2(i, j, movies)
ii <- c(ii, i)
jj <- c(jj, j)
pp <- c(pp, pval)
}
}
tibble(ii, jj, pp)This is a lot of fiddling about, since you have to initialize three vectors, and then update them every time through the loop. It’s hard to read, because the actual business part of the loop is the calculation of the P-value, and that’s almost hidden by all the book-keeping. (It’s also slow and inefficient, though the slowness doesn’t matter too much here since it’s not a very big problem.)
Let’s try another way:
crossing(first = the_ratings, second = the_ratings)crossing is a sort of model-free version of datagrid: it works out all possible combinations of whatever vectors you feed it (that don’t have to be the same, but here are).
We don’t actually need all of that; we just need the ones where the first one is (alphabetically) strictly less than the second one. This is because we’re never comparing a rating with itself, and each pair of ratings appears twice, once in alphabetical order, and once the other way around. The ones we need are these:
crossing(first = the_ratings, second = the_ratings) %>%
filter(first < second)A technique thing to note: instead of asking “how do I pick out the distinct pairs of ratings?”, I use two simpler tools: first I make all the combinations of pairs of ratings, and then out of those, pick the ones that are alphabetically in ascending order, which we know how to do.
Now we want to call our function comp2 for each of the things in first and each of the things in second, and make a new column called pval that contains exactly that. comp2 expects single movie ratings for each of its inputs, not a vector of each, so the way to go about this is rowwise:
crossing(first = the_ratings, second = the_ratings) %>%
filter(first < second) %>%
rowwise() %>%
mutate(pval = comp2(first, second, movies))One more thing: we’re doing 6 tests at once here, so we’re giving ourselves 6 chances to reject a null (all medians equal) that might have been true. So the true probability of a type I error is no longer 0.05 but something bigger.
The easiest way around that is to do a so-called Bonferroni adjustment: instead of rejecting if the P-value is less than 0.05, we only reject if it is less than \(0.05/6\), since we are doing 6 tests. This is a fiddly calculation to do by hand, but it’s easy to build in another mutate, thus:7
crossing(first = the_ratings, second = the_ratings) %>%
filter(first < second) %>%
rowwise() %>%
mutate(pval = comp2(first, second, movies)) %>%
mutate(reject = (pval < 0.05 / 6))And not a loop in sight.
This is how I coded it in pairwise_median_test. If you want to check it, it’s on Github: link. The function median_test_pair is the same as comp2 above.
So the only significant differences are now G compared to PG and PG-13. There is not a significant difference in median movie length between G and R, though it is a close call. We thought the PG-13 movies might have a significantly different median from other rating groups beyond G, but they turn out not to have. (The third and fourth comparisons would have been significant had we not made the Bonferroni adjustment to compensate for doing six tests at once; with that adjustment, we only reject if the P-value is less than \(0.05/6=0.0083\), and so 0.0106 is not quite small enough to reject with.)
Listing the rating groups sorted by median would give you an idea of how far different the medians have to be to be significantly different:
medians <- movies %>%
group_by(rating) %>%
summarize(med = median(length)) %>%
arrange(desc(med))
mediansSomething rather interesting has happened: even though the comparison of G and PG (18 apart) is significant, the comparison of G and R (21 apart) is not significant. This seems very odd, but it happens because the Mood median test is not actually literally comparing the sample medians, but only assessing the splits of values above and below the median of the combined sample. A subtlety, rather than an error, I’d say.
Here’s something extremely flashy to finish with:
crossing(first = the_ratings, second = the_ratings) %>%
filter(first < second) %>%
rowwise() %>%
mutate(pval = comp2(first, second, movies)) %>%
mutate(reject = (pval < 0.05 / 6)) %>%
left_join(medians, join_by(first == rating)) %>%
left_join(medians, join_by(second == rating))The additional two lines look up the medians of the rating groups in first, then second, so that you can see the actual medians of the groups being compared each time. You see that medians different by 30 are definitely different, ones differing by 15 or less are definitely not different, and ones differing by about 20 could go either way.
I think that’s quite enough of that.
\(\blacksquare\)
13.13 Atomic weight of carbon
The atomic weight of the chemical element carbon is 12. Two methods of measuring the atomic weight of samples of carbon were compared. The results are shown in link. The methods are labelled 1 and 2. The first task is to find out whether the two methods have different “typical” measures (mean or median, as appropriate) of the atomic weight of carbon.
For this question, compose a report in a Quarto document. ( See part (a) for how to get this started.
Your report should read like an actual report, not just the answers to some questions that I set you. To help with that, write some text that links the parts of the report together smoothly, so that it reads as a coherent whole. The grader had 3 discretionary marks to award for the overall quality of your writing. The scale for this was:
3 points: excellent writing. The report flows smoothly, is easy to read, and contains everything it should (and nothing it shouldn’t).
2 points: satisfactory writing. Not the easiest to read, but says what it should, and it looks at least somewhat like a report rather than a string of answers to questions.
1 point: writing that is hard to read or to understand. If you get this (or 0), you should consider what you need to do to improve when you write your project.
0 points: you answered the questions, but you did almost nothing to make it read like a report.
- Create a new Quarto document. To do this, in R Studio, select File, New File, Quarto Document. Type the report title and your name in the boxes, and leave the output on the default HTML. Click OK.
Solution
You’ll see the title and your name in a section at the top of the document, and below that you’ll see a template document.
\(\blacksquare\)
- Write an introduction that explains the purpose of this study and the data collected in your own words.
Solution
Something like this:
This study is intended to compare two different methods (labelled 1 and 2) for measuring the atomic weight of carbon (which is known in actual fact to be 12). Fifteen samples of carbon were used; ten of these were assessed using method 1 and the remaining five using method 2. The primary interest in this particular study is to see whether there is a difference in the mean or median atomic weight as measured by the two methods.
Before that, start a new section like this: ## Introduction. Also, get used to expressing your understanding in your words, not mine. Using my words, in my courses, is likely to be worth very little.
\(\blacksquare\)
- Begin an appropriately-titled new section in your report, read the data into R and display the results.
Solution
Values separated by spaces:
my_url <- "http://ritsokiguess.site/datafiles/carbon.txt"
carbon <- read_delim(my_url, " ")Rows: 15 Columns: 2
── Column specification ────────────────────────────────────────────────────────
Delimiter: " "
dbl (2): method, weight
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.carbonI would expect you to include, without being told to include it, some text in your report indicating that you have sensible data: two methods labelled 1 and 2 as promised, and a bunch8 of atomic weights close to the nominal figure of 12.
\(\blacksquare\)
- Make an appropriate plot to compare the measurements obtained by the two methods. You might need to do something about the two methods being given as numbers even though they are really only identifiers. (If you do, your report ought to say what you did and why.)
Solution
The appropriate plot, with a categorical method and quantitative weight, is something like a boxplot. If you’re not careful, method will get treated as a quantitative variable, which you don’t want; the easiest way around that, for a boxplot at least, is to turn it into a factor like this:
ggplot(carbon, aes(x = factor(method), y = weight)) + geom_boxplot()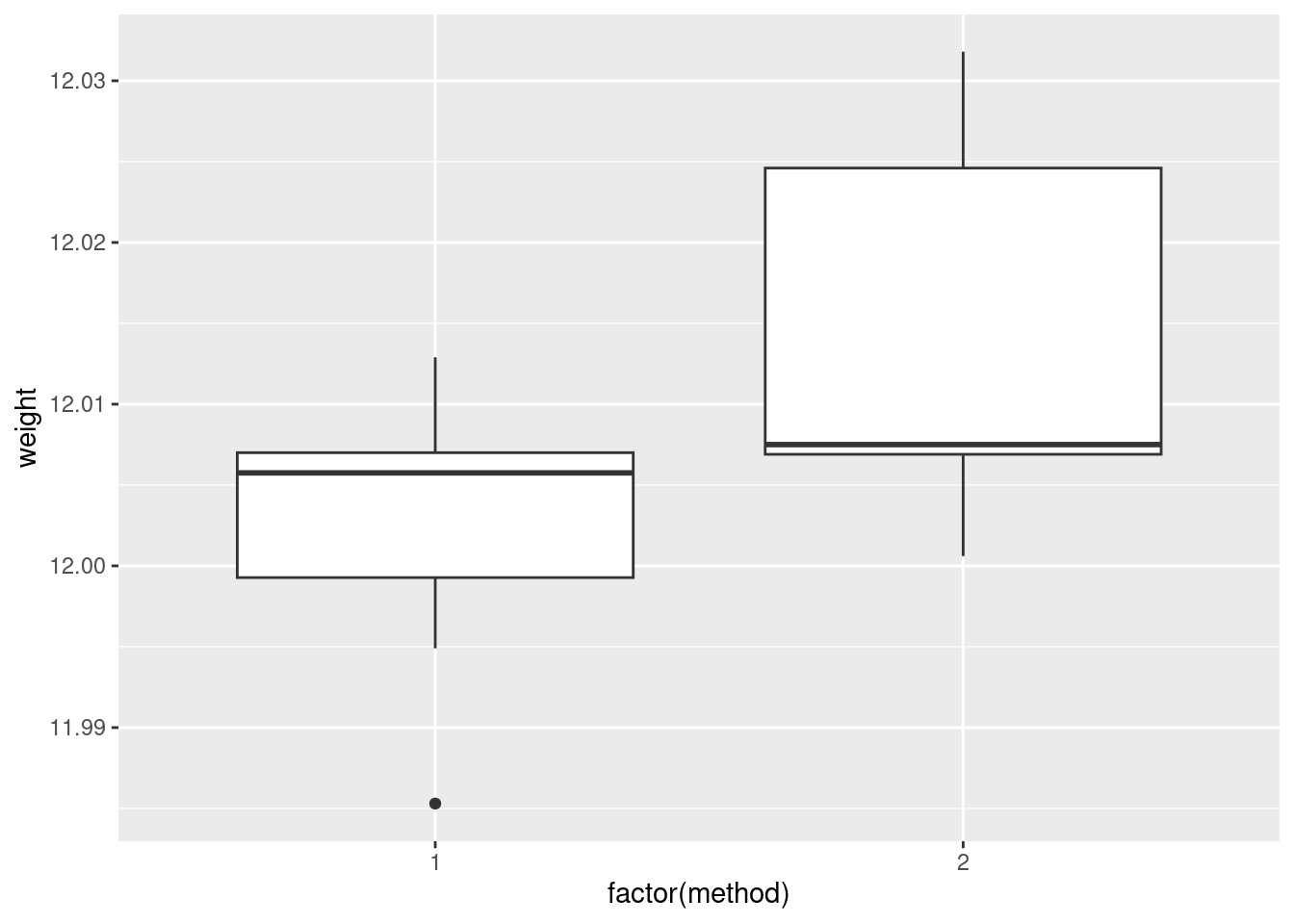
If you insist, you could do a faceted histogram (above and below, for preference):
ggplot(carbon, aes(x = weight)) + geom_histogram(bins = 5) +
facet_wrap(~method, ncol = 1)
There are really not enough data values for a histogram to be of much help, so I don’t like this as much.
If you are thinking ahead (we are going to be doing a \(t\)-test), then you’ll realize that normality is the kind of thing we’re looking for, in which case normal quantile plots would be the thing. However, we might have to be rather forgiving for method 2 since there are only 5 observations:
ggplot(carbon, aes(sample = weight)) +
stat_qq() + stat_qq_line() +
facet_wrap(~method)
I don’t mind these coming out side by side, though I would rather have them squarer.
I would say, boxplots are the best, normal quantile plots are also acceptable, but expect to lose something for histograms because they offer only a rather crude comparison in this case.
\(\blacksquare\)
- Comment briefly on what you see in your plot.
Solution
In boxplots, if that’s what you drew, there are several things that deserve comment: the medians, the spreads and the shapes. The median for method 1 is a little bit lower than for method 2 (the means are probably more different, given the shapes of the boxes). The spread for method 2 is a lot bigger. (Looking forward, that suggests a Welch-Satterthwaite rather than a pooled test.) As for shape, the method 2 measurements seem more or less symmetric (the whiskers are equal anyway, even if the position of the median in the box isn’t), but the method 1 measurements have a low outlier. The histograms are hard to compare. Try to say something about centre and spread and shape. I think the method 2 histogram has a slightly higher centre and definitely bigger spread. On my histogram for method 1, the distribution looks skewed left. If you did normal quantile plots, say something sensible about normality for each of the two methods. For method 1, I would say the low value is an outlier and the rest of the values look pretty straight. Up to you whether you think there is a curve on the plot (which would indicate skewness, but then that highest value is too high: it would be bunched up with the other values below 12.01 if there were really skewness). For method 2, it’s really hard to say anything since there are only five values. Given where the line goes, there isn’t much you can say to doubt normality. Perhaps the best you can say here is that in a sample of size 5, it’s difficult to assess normality at all.
\(\blacksquare\)
- Carry out the most appropriate \(t\)-test. (You might like to begin another new section in your report here.)
Solution
This would be the Welch-Satterthwaite version of the two-sample \(t\)-test, since the two groups do appear to have different spreads:
t.test(weight ~ method, data = carbon)
Welch Two Sample t-test
data: weight by method
t = -1.817, df = 5.4808, p-value = 0.1238
alternative hypothesis: true difference in means between group 1 and group 2 is not equal to 0
95 percent confidence interval:
-0.027777288 0.004417288
sample estimates:
mean in group 1 mean in group 2
12.00260 12.01428 Imagining that this is a report that would go to your boss, you ought to defend your choice of the Welch-Satterthwaite test (as I did above), and not just do the default \(t\)-test without comment.
If, in your discussion above, you thought the spreads were equal enough, then you should do the pooled \(t\)-test here, which goes like this:
t.test(weight ~ method, data = carbon, var.equal = T)
Two Sample t-test
data: weight by method
t = -2.1616, df = 13, p-value = 0.04989
alternative hypothesis: true difference in means between group 1 and group 2 is not equal to 0
95 percent confidence interval:
-2.335341e-02 -6.588810e-06
sample estimates:
mean in group 1 mean in group 2
12.00260 12.01428 The point here is that you should do the right test based on your conclusion. Being consistent is the most important thing. (In this case, note that the P-values are very different. We’ll get to that shortly.)
You might think we should do a test that compares the two variances, so that then we’d know which flavour of test to do. Such tests exist, but I feel that it’s just as good to eyeball the spreads and make a call about whether they are “reasonably close”. Or even, to always do the Welch-Satterthwaite test on the basis that it is pretty good even if the two populations have the same variance. (If this last point of view is one that you share, you ought to say something about that when you do your \(t\)-test.) The problem is that doing a test to decide which test to do can change the actual P-value from what the output of your second test says; the second test, as far as R is concerned, is done without knowledge that you did another test first.
Extra: I guess this is a good place to say something about tests for comparing variances, given that you might be pondering that. There are several that I can think of, that R can do, of which I mention two.
The first is the \(F\)-test for variances that you might have learned in B57 (that is the basis for the ANOVA \(F\)-test):
var.test(weight ~ method, data = carbon)
F test to compare two variances
data: weight by method
F = 0.35768, num df = 9, denom df = 4, p-value = 0.1845
alternative hypothesis: true ratio of variances is not equal to 1
95 percent confidence interval:
0.04016811 1.68758230
sample estimates:
ratio of variances
0.3576842 This, unfortunately, is rather dependent on the data in the two groups being approximately normal. Since we are talking variances rather than means, there is no Central Limit Theorem to rescue us for large samples (quite aside from the fact that these samples are not large). Since the ANOVA \(F\)-test is based on the same theory, this is why normality is also more important in ANOVA than it is in a \(t\)-test.
The second is Levene’s test. This doesn’t depend on normality (at least, not nearly so much), so I like it better in general:
library(car)
leveneTest(weight ~ factor(method), data = carbon)Levene’s test takes a different approach: first the absolute differences from the group medians are calculated, and then an ANOVA is run on the absolute differences. If, say, one of the groups has a larger spread than the other(s), its absolute differences from the median will tend to be bigger.9 As for what we conclude here, well, neither of the variance tests show any significance at all, so from that point of view there is no evidence against using the pooled \(t\)-test. Having said that, the samples are small, and so it would be difficult to prove that the two methods have different variance, even if they actually did.10
Things are never as clear-cut as you would like. In the end, it all comes down to making a call and defending it.
\(\blacksquare\)
- Do the most appropriate test you know that does not assume normally-distributed data.
Solution
That would be Mood’s median test. Since I didn’t say anything about building it yourself, feel free to use smmr:
library(smmr)
median_test(carbon, weight, method)$grand_median
[1] 12.0064
$table
above
group above below
1 3 6
2 4 1
$test
what value
1 statistic 2.80000000
2 df 1.00000000
3 P-value 0.09426431As an aside, if you have run into a non-parametric test such as Mann-Whitney or Kruskal-Wallis that applies in this situation, be careful about using it here, because they have additional assumptions that you may not want to trust. Mann-Whitney started life as a test for “equal distributions”.11 This means that the null is equal location and equal spread, and if you reject the null, one of those has failed. But here, we suspect that equal spread will fail, so that the Mann-Whitney test may end up rejecting whether or not the medians are different, so it won’t answer the question you want an answer to. Mood’s median test doesn’t have that problem; all it’s saying if the null is true is that the medians are equal; the spreads could be anything at all.
The same kind of issues apply to the signed-rank test vs. the sign test. In the case of the signed-rank test, the extra assumption is of a symmetric distribution — to my mind, if you don’t believe normality, you probably don’t have much confidence in symmetry either. That’s why I like the sign test and Mood’s median test: in the situation where you don’t want to be dealing with assumptions, these tests don’t make you worry about that.
Another comment that you don’t need to make is based on the not-quite-significance of the Mood test. The P-value is less than 0.10 but not less than 0.05, so it doesn’t quite reach significance by the usual standard. But if you look up at the table, the frequencies seem rather unbalanced: 6 out of the remaining 9 weights in group 1 are below the overall median, but 4 out of 5 weights in group 2 are above. This seems as if it ought to be significant, but bear in mind that the sample sizes are small, and thus Mood’s median test needs very unbalanced frequencies, which we don’t quite have here.
\(\blacksquare\)
- Discuss the results of your tests and what they say about the two methods for measuring the atomic weight of carbon. If it seems appropriate, put the discussion into a section called Conclusions.
Solution
Begin by pulling out the P-values for your preferred test(s) and say what they mean. The P-value for the Welch-Satterthwaite \(t\)-test is 0.1238, which indicates no difference in mean atomic weights between the two methods. The Mood median test gives a similarly non-significant 0.0943, indicating no difference in the median weights. If you think both tests are plausible, then give both P-values and do a compare-and-contrast with them; if you think that one of the tests is clearly preferable, then say so (and why) and focus on that test’s results.
If you thought the pooled test was the right one, then you’ll have a bit more discussion to do, since its P-value is 0.0499, and at \(\alpha=0.05\) this test disagrees with the others. If you are comparing this test with the Mood test, you ought to make some kind of reasoned recommendation about which test to believe.
As ever, be consistent in your reasoning.
Extra: this dataset, where I found it, was actually being used to illustrate a case where the pooled and the Welch-Satterthwaite tests disagreed. The authors of the original paper that used this dataset (a 1987 paper by Best and Rayner;12 the data come from 1924!) point out that the pooled \(t\)-test can be especially misleading when the smaller sample is also the one with the larger variance. This is what happened here.
In the Best and Rayner paper, the Mood (or the Mann-Whitney) test was not being considered, but I think it’s good practice to draw a picture and make a call about which test is appropriate.
\(\blacksquare\)
13.14 Can caffeine improve your performance on a test?
Does caffeine help students do better on a certain test? To find out, 36 students were randomly allocated to three groups (12 in each group). Each student received a fixed number of cups of coffee while they were studying, but the students didn’t know whether they were receiving all full-strength coffee (“high”), all decaf coffee (“low”) or a 50-50 mixture of the two (“moderate”). For each subject, their group was recorded as well as their score on the test. The data are in link, as a .csv file.
- Read in and examine the data. How are the values laid out?
Solution
read_csv because it’s a .csv file:
my_url <- "http://ritsokiguess.site/datafiles/caffeine.csv"
caffeine.untidy <- read_csv(my_url)Rows: 12 Columns: 4
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
dbl (4): Sub, High, Moderate, None
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.caffeine.untidyThe first column is the number of the subject (actually within each group, since each student only tried one amount of caffeine). Then follow the test scores for the students in each group, one group per column.
I gave the data frame a kind of dumb name, since (looking ahead) I could see that I would need a less-dumb name for the tidied-up data, and it seemed sensible to keep caffeine for that.
\(\blacksquare\)
- Explain briefly how the data are not “tidy”.
Solution
The last three columns are all scores on the test: that is, they all measure the same thing, so they should all be in the same column. Or, there should be a column of scores, and a separate column naming the groups. Or, there were 36 observations in the data, so there should be 36 rows. You always have a variety of ways to answer these, any of which will do.
\(\blacksquare\)
- Use a suitable tool from the
tidyverseto create one column of test scores and and one column of group labels. Call your column of group labelsamount. Is it afactor?
Solution
We are combining several columns into one, so this is pivot_longer:
caffeine.untidy %>%
pivot_longer(-Sub, names_to = "amount", values_to = "score") -> caffeineI didn’t ask you to list the resulting data frame, but it is smart to at least look for yourself, to make sure pivot_longer has done what you expected.
caffeineA column of amounts of caffeine, and a column of test scores. This is what we expected. There should be 12 each of the amounts, which you can check if you like:
caffeine %>% count(amount)Indeed.
Note that amount is text, not a factor. Does this matter? We’ll see.
This is entirely the kind of situation where you need pivot_longer, so get used to seeing where it will be useful.
\(\blacksquare\)
- Obtain side-by-side boxplots of test scores by amount of caffeine.
Solution
ggplot(caffeine, aes(x = amount, y = score)) + geom_boxplot()
Note that this is much more difficult if you don’t have a tidy data frame. (Try it and see.)
\(\blacksquare\)
- Does caffeine amount seem to have an effect? If so, what kind of effect?
Solution
On average, exam scores seem to be higher when the amount of caffeine is higher (with the effect being particularly pronounced for High caffeine). If you want to, you can also say the the effect of caffeine seems to be small, relative to the amount of variability there is (there is a lot). The point is that you say something supported by the boxplot.
\(\blacksquare\)
- Run a suitable analysis of variance to determine whether the mean test score is equal or unequal for the three groups. What do you conclude?
Solution
Something like this:
caff.1 <- aov(score ~ amount, data = caffeine)
summary(caff.1) Df Sum Sq Mean Sq F value Pr(>F)
amount 2 477.7 238.86 3.986 0.0281 *
Residuals 33 1977.5 59.92
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1The P-value on the \(F\)-test is less than 0.05, so we reject the null hypothesis (which says that all the groups have equal means) in favour of the alternative: the group means are not all the same (one or more of them is different from the others).
Notice that the boxplot and the aov are quite happy for amount to be text rather than a factor (they actually do want a factor, but if the input is text, they’ll create one).
\(\blacksquare\)
- Why is it a good idea to run Tukey’s method here?
Solution
The analysis of variance \(F\)-test is significant, so that the groups are not all the same. Tukey’s method will tell us which group(s) differ(s) from the others. There are three groups, so there are differences to find that we don’t know about yet.
\(\blacksquare\)
- Run Tukey’s method. What do you conclude?
Solution
This kind of thing:
caff.3 <- TukeyHSD(caff.1)
caff.3 Tukey multiple comparisons of means
95% family-wise confidence level
Fit: aov(formula = score ~ amount, data = caffeine)
$amount
diff lwr upr p adj
Moderate-High -4.750000 -12.50468 3.004679 0.3025693
None-High -8.916667 -16.67135 -1.161987 0.0213422
None-Moderate -4.166667 -11.92135 3.588013 0.3952176The high-caffeine group definitely has a higher mean test score than the no-caffeine group. (The Moderate group is not significantly different from either of the other groups.) Both the comparisons involving Moderate could go either way (the interval for the difference in means includes zero). The None-High comparison, however, is away from zero, so this is the significant one. As is usual, we are pretty sure that the difference in means (this way around) is negative, but we are not at all clear about how big it is, because the confidence interval is rather long.13
Extra: the normality and equal spreads assumptions look perfectly good, given the boxplots, and I don’t think there’s any reason to consider any other test. You might like to assess that with normal quantile plots:
ggplot(caffeine, aes(sample=score)) + stat_qq() +
stat_qq_line() + facet_wrap(~amount, ncol=2)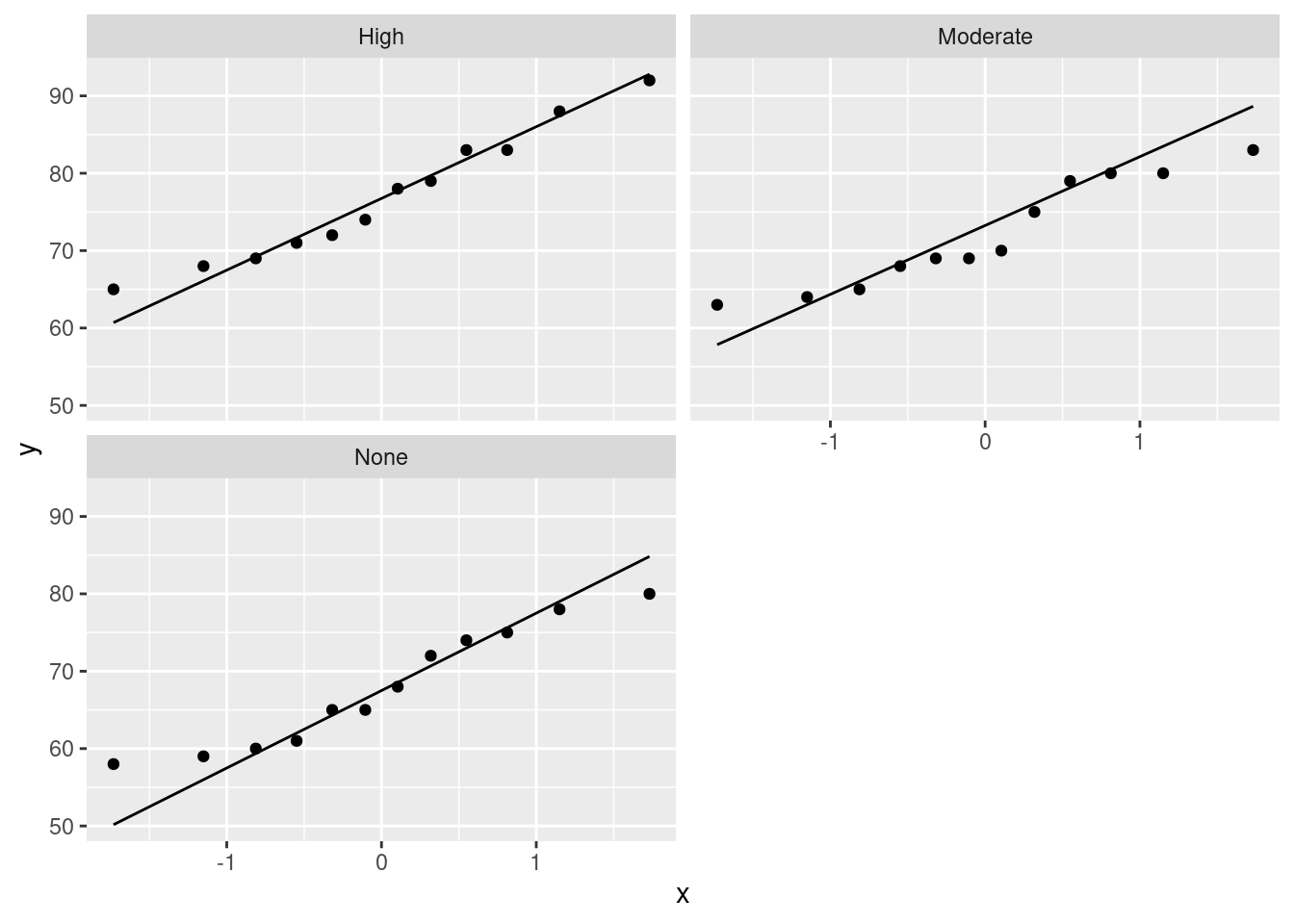
There’s nothing to worry about there normality-wise. If anything, there’s a little evidence of short tails (in the None group especially), but you’ll recall that short tails don’t affect the mean and thus pose no problems for the ANOVA. Those three lines also have pretty much the same slope, indicating very similar spreads. Regular ANOVA is the best test here. (Running eg. Mood’s median test would be a mistake here, because it doesn’t use the data as efficiently (counting only aboves and belows) as the ANOVA does, and so the ANOVA will give a better picture of what differs from what.)
\(\blacksquare\)
13.15 Reggae music
Reggae is a music genre that originated in Jamaica in the late 1960s. One of the most famous reggae bands was Bob Marley and the Wailers. In a survey, 729 students were asked to rate reggae music on a scale from 1, “don’t like it at all” to 6, “like it a lot”. We will treat the ratings as quantitative. Each student was also asked to classify their home town as one of “big city”, “suburban”, “small town”, “rural”. Does a student’s opinion of reggae depend on the kind of home town they come from? The data are in http://ritsokiguess.site/datafiles/reggae.csv.
- Read in and display (some of) the data.
Solution
This is (evidently) a .csv, so:
my_url <- "http://ritsokiguess.site/datafiles/reggae.csv"
reggae <- read_csv(my_url)Rows: 729 Columns: 2
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (1): home
dbl (1): rating
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.reggaeThe students shown are all from big cities, but there are others, as you can check by scrolling down.
\(\blacksquare\)
- How many students are from each different size of town?
Solution
This is the usual kind of application of count:
reggae %>% count(home)Another, equally good, way (you can ignore the warning):
reggae %>% group_by(home) %>%
summarize(n=n())Most of the students in this data set are from suburbia.
\(\blacksquare\)
- Make a suitable graph of the two variables in this data frame.
Solution
One quantitative, one categorical: a boxplot, as ever:
ggplot(reggae, aes(x=home, y=rating)) + geom_boxplot()
Extra 1: the last three boxplots really are identical, because the medians, means, quartiles and extreme values are all equal. However, the data values are not all the same, as you see below.
Extra 2: I said that the ratings should be treated as quantitative, to guide you towards this plot. You could otherwise have taken the point of view that the ratings were (ordered) categorical, in which case the right graph would have been a grouped bar chart, as below. There is a question about which variable should be x and which should be fill. I am taking the point of view that we want to compare ratings within each category of home, which I think makes sense here (see discussion below), which breaks my “rule” that the categorical variable with fewer categories should be x.14
ggplot(reggae, aes(x=home, fill=factor(rating))) + geom_bar(position = "dodge")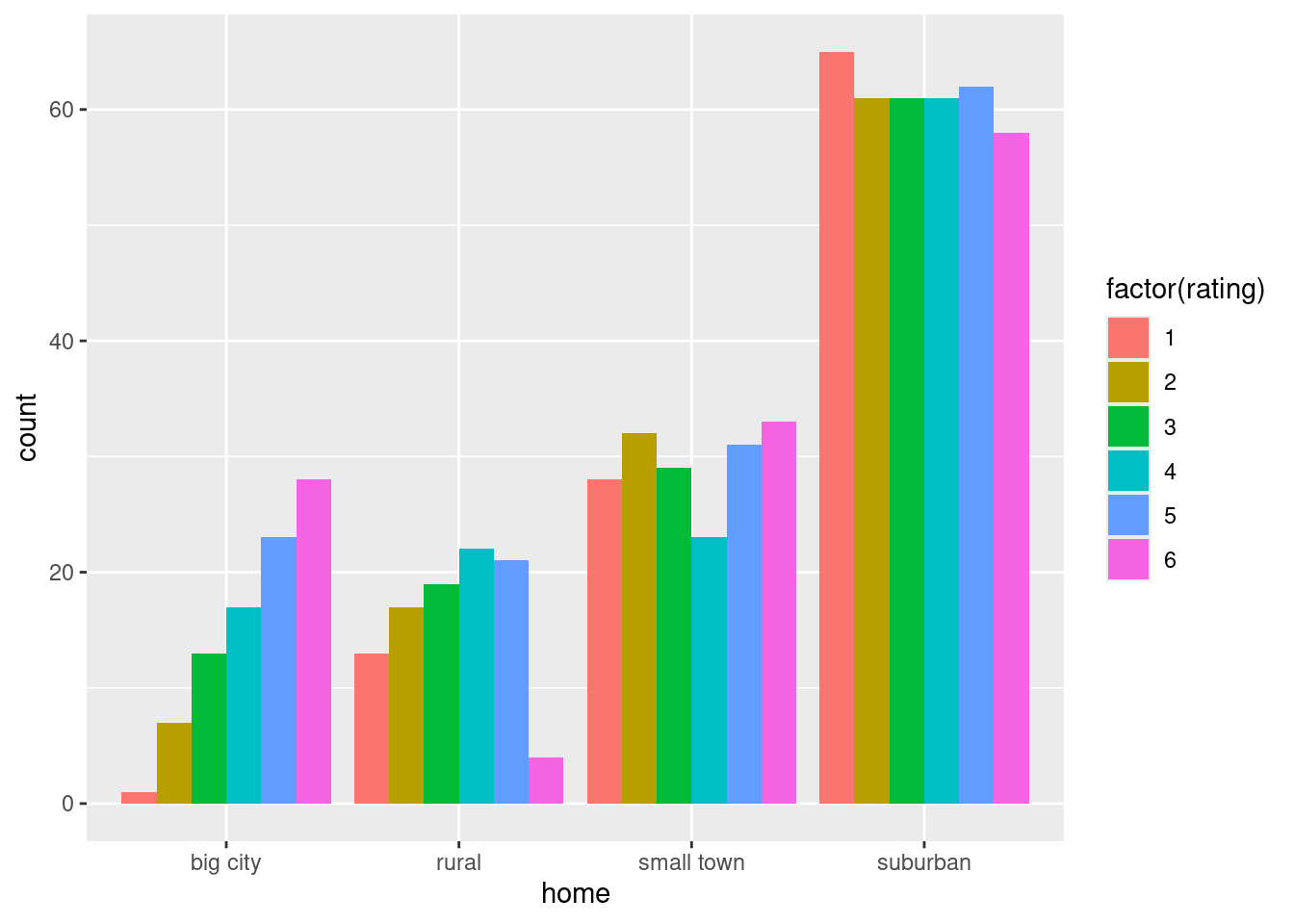
\(\blacksquare\)
- Discuss briefly why you might prefer to run Mood’s median test to compare ratings among home towns.
Solution
The issue here is whether all of the rating distributions (within each category of home) are sufficiently close to normal in shape. The “big city” group is clearly skewed to the left. This is enough to make us favour Mood’s median test over ANOVA.
A part-marks answer is to note that the big-city group has smaller spread than the other groups (as measured by the IQR). This is answering the wrong question, though. Remember the process: first we assess normality. If that fails, we use Mood’s median test. Then, with normality OK, we assess equal spreads. If that fails, we use Welch ANOVA, and if both normality and equal spreads pass, we use regular ANOVA.
\(\blacksquare\)
- Suppose that somebody wanted to run Welch ANOVA on these data. What would be a reasonable argument to support that?
Solution
The argument would have to be that normality is all right, given the sample sizes. We found earlier that there are between 89 and 368 students in each group. These are large samples, and might be enough to overcome the non-normality we see.
The only real concern I have is with the big city group. This is the least normal, and also the smallest sample. The other groups seem to have the kind of non-normality that will easily be taken care of by the sample sizes we have.
Extra: the issue is really about the sampling distribution of the mean within each group. Does that look normal enough? This could be assessed by looking at each group, one at a time, and taking bootstrap samples. Here’s the big-city group:
reggae %>% filter(home=="big city") -> bigs
tibble(sim = 1:1000) %>%
rowwise() %>%
mutate(my_sample = list(sample(bigs$rating, replace = T))) %>%
mutate(my_mean = mean(my_sample)) %>%
ggplot(aes(x = my_mean)) + geom_histogram(bins = 12)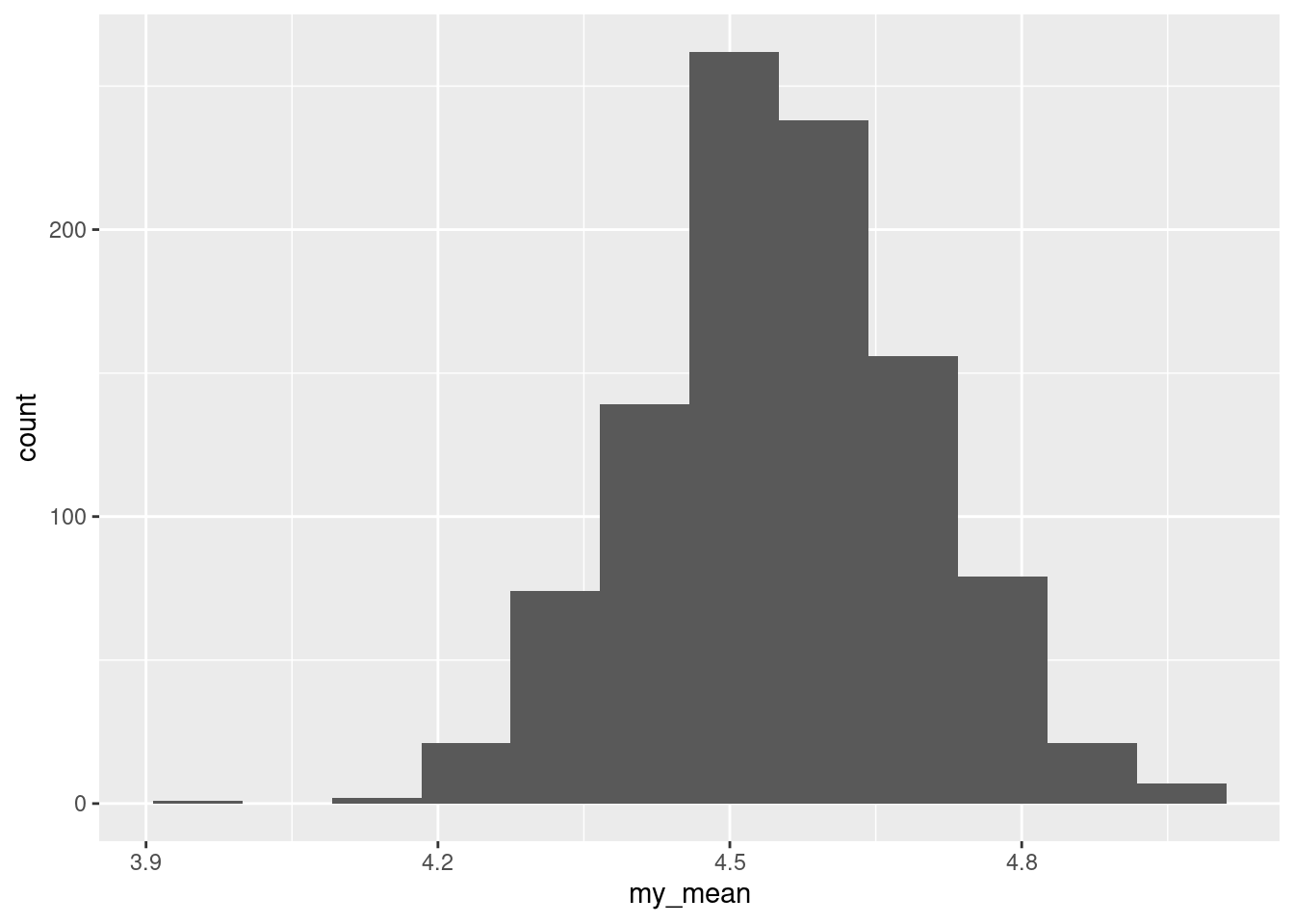
Not too much wrong with that. This shows that the sample size is indeed big enough to cope with the skewness.
You can do any of the others the same way.
If you’re feeling bold, you can get hold of all three bootstrapped sampling distributions at once, like this:
reggae %>%
nest_by(home) %>%
mutate(sim = list(1:1000)) %>%
unnest(sim) %>%
rowwise() %>%
mutate(my_sample = list(sample(data$rating, replace = TRUE))) %>%
mutate(my_mean = mean(my_sample)) %>%
ggplot(aes(x = my_mean)) + geom_histogram(bins = 12) +
facet_wrap(~home, scales = "free")
All of these distributions look very much normal, so there is no cause for concern anywhere.
This was rather a lot of code, so let me take you through it. The first thing is that we want to treat the different students’ homes separately, so the first step is this:
reggae %>%
nest_by(home) This subdivides the students’ reggae ratings according to where their home is. The things in data are data frames containing a column rating for in each case the students who had the home shown.
Normally, we would start by making a dataframe with a column called sim that labels the 1000 or so simulations. This time, we want four sets of simulations, one for each home, which we can set up this way:
reggae %>%
nest_by(home) %>%
mutate(sim = list(1:1000)) The definition of sim happens by group, or rowwise, by home (however you want to look at it). Next, we need to spread out those sim values so that we’ll have one row per bootstrap sample:
reggae %>%
nest_by(home) %>%
mutate(sim = list(1:1000)) %>%
unnest(sim) \(4 \times 1000 = 4000\) rows. Note that the data column now contains multiple copies of all the ratings for the students with that home, which seems wasteful, but it makes our life easier because what we want is a bootstrap sample from the right set of students, namely the rating column from the dataframe data in each row. Thus, from here out, everything is the same as we have done before: work rowwise, get a bootstrap sample , find its mean, plot it. The one thing we need to be careful of is to make a separate histogram for each home, since each of the four distributions need to look normal. I used different scales for each one, since they are centred in different places; this has the side benefit of simplifying the choice of the number of bins. (See what happens if you omit the scales = "free".)
In any case, all is absolutely fine. We’ll see how this plays out below.
\(\blacksquare\)
- Run Mood’s median test and display the output.
Solution
Data frame, quantitative column, categorical column:
median_test(reggae, rating, home)$grand_median
[1] 4
$table
above
group above below
big city 51 21
rural 25 49
small town 64 89
suburban 120 187
$test
what value
1 statistic 2.733683e+01
2 df 3.000000e+00
3 P-value 5.003693e-06\(\blacksquare\)
- Explain briefly why running pairwise median tests is a good idea, run them, and display the results.
Solution
The Mood’s median test is significant, with a P-value of 0.000005, so the median ratings are not all the same. We want to find out how they differ.
(The table of aboves and belows, and for that matter the boxplot earlier, suggest that big-city will be different from the rest, but it is not clear whether there will be any other significant differences.)
pairwise_median_test(reggae, rating, home)\(\blacksquare\)
- Summarize, as concisely as possible, how the home towns differ in terms of their students’ ratings of reggae music.
Solution
The students from big cities like reggae more than students from other places. The other kinds of hometown do not differ significantly.
Extra 1: Given the previous discussion, you might be wondering how Welch ANOVA (and maybe even regular ANOVA) compare. Let’s find out:
oneway.test(rating~home,data=reggae)
One-way analysis of means (not assuming equal variances)
data: rating and home
F = 16.518, num df = 3.00, denom df = 257.07, p-value = 7.606e-10and
gamesHowellTest(rating~factor(home),data=reggae)
Pairwise comparisons using Games-Howell testdata: rating by factor(home) big city rural small town
rural 1.1e-07 - -
small town 2.9e-06 0.74 -
suburban 4.9e-09 0.91 0.94
P value adjustment method: nonealternative hypothesis: two.sidedThe conclusions are identical with Mood’s median test, and the P-values are not that different, either.
This makes me wonder how an ordinary ANOVA with Tukey would have come out:
reggae %>%
aov(rating~home, data=.) %>%
TukeyHSD() Tukey multiple comparisons of means
95% family-wise confidence level
Fit: aov(formula = rating ~ home, data = .)
$home
diff lwr upr p adj
rural-big city -1.20681180 -1.8311850 -0.5824386 0.0000048
small town-big city -1.00510725 -1.5570075 -0.4532070 0.0000194
suburban-big city -1.09404006 -1.5952598 -0.5928203 0.0000002
small town-rural 0.20170455 -0.3366662 0.7400753 0.7695442
suburban-rural 0.11277174 -0.3735106 0.5990540 0.9329253
suburban-small town -0.08893281 -0.4778062 0.2999406 0.9354431Again, almost identical.
Extra 2: some Bob Marley and the Wailers for you:
Reggae music at its finest.
\(\blacksquare\)
13.16 Watching TV and education
The General Social Survey is a large survey of a large number of people. One of the questions on the survey is “how many hours of TV do you watch in a typical day?” Another is “what is your highest level of education attained”, on this scale:
- HSorLess: completed no more than high h school
- College: completed some form of college, either a community college (like Centennial) or a four-year university (like UTSC)
- Graduate: completed a graduate degree such as an MSc.
Do people with more education tend to watch more TV? We will be exploring this. The data are in http://ritsokiguess.site/datafiles/gss_tv.csv.
- Read in and display (some of) the data.
Solution
Exactly the usual:
my_url <- "http://ritsokiguess.site/datafiles/gss_tv.csv"
gss <- read_csv(my_url)Rows: 905 Columns: 2
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (1): degree
dbl (1): tvhours
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.gss\(\blacksquare\)
- For each level of education, obtain the number of observations, the mean and the median of the number of hours of TV watched.
Solution
group_by and summarize, using n() to get the number of observations (rather than count because you want some numerical summaries as well):
gss %>% group_by(degree) %>%
summarise(n=n(), mean=mean(tvhours), med=median(tvhours))\(\blacksquare\)
- What does your answer to the previous part tell you about the shapes of the distributions of the numbers of hours of TV watched? Explain briefly.
Solution
In each of the three groups, the mean is greater than the median, so I think the distributions are skewed to the right. Alternatively, you could say that you expect to see some outliers at the upper end.
\(\blacksquare\)
- Obtain a suitable graph of your data frame.
Solution
One quantitative variable and one categorical one, so a boxplot. (I hope you are getting the hang of this by now.)
ggplot(gss, aes(x=degree, y=tvhours)) + geom_boxplot()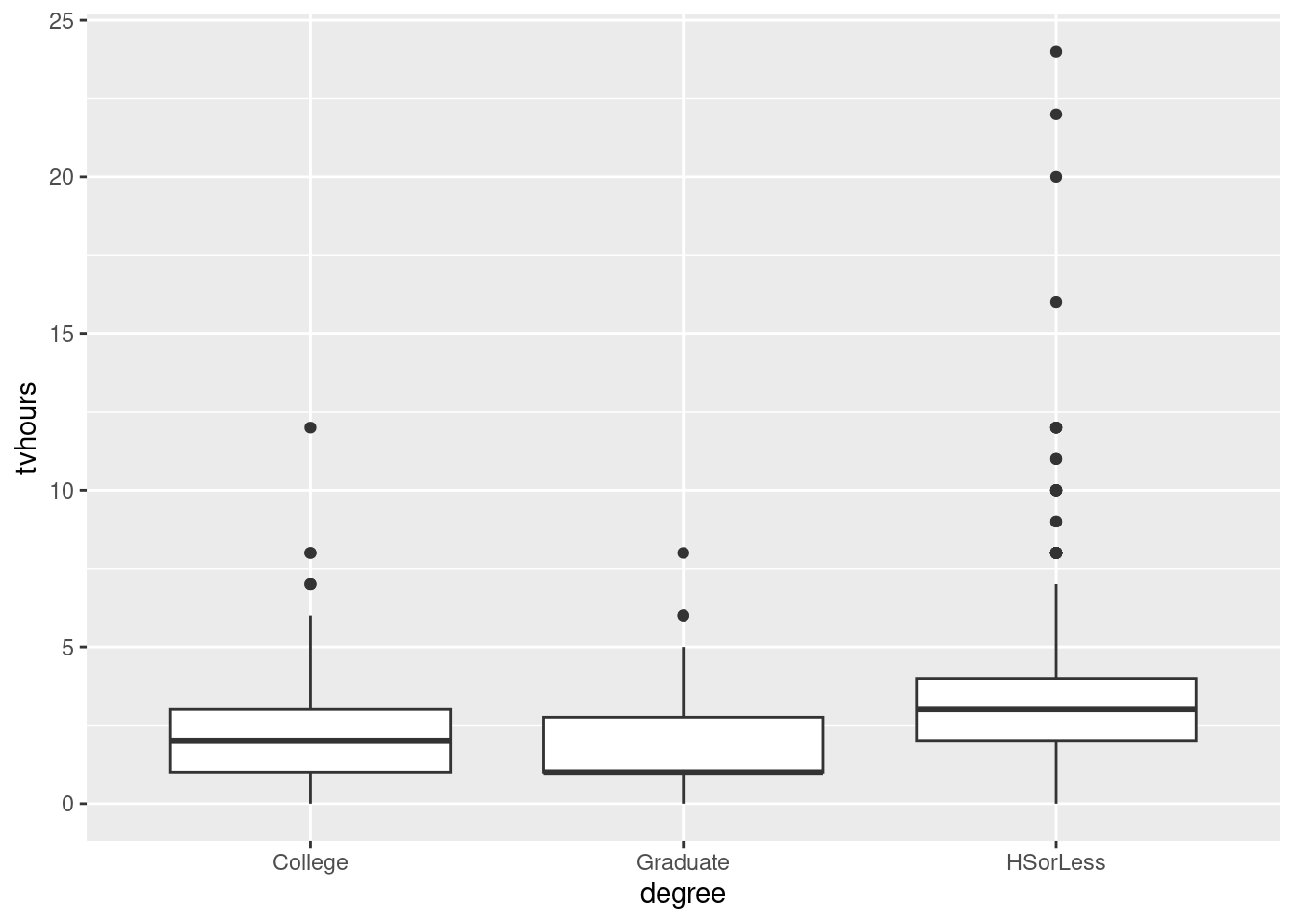
\(\blacksquare\)
- Does your plot indicate that your guess about the distribution shape was correct? Explain briefly.
Solution
I guessed before that the distributions would be right-skewed, and they indeed are, with the long upper tails. Or, if you suspected upper outliers, they are here as well.
Say what you guessed before, and how your graph confirms it (or doesn’t, if it doesn’t.)
\(\blacksquare\)
- Run a suitable test to compare the average number of hours of TV watched for people with each amount of education. (“Average” could be mean or median, whichever you think is appropriate.)
Solution
From the boxplot, the distributions are definitely not all normal; in fact, none of them are. So we should use Mood’s median test, thus:
median_test(gss, tvhours, degree)$grand_median
[1] 2
$table
above
group above below
College 67 70
Graduate 18 36
HSorLess 355 126
$test
what value
1 statistic 5.608269e+01
2 df 2.000000e+00
3 P-value 6.634351e-13\(\blacksquare\)
- What do you conclude from your test, in the context of the data?
Solution
The P-value of \(6.6\times 10^{-13}\) is extremely small, so we conclude that not all of the education groups watch the same median amount of TV. Or, there are differences in the median amount of TV watched among the three groups.
An answer of “the education groups are different” is wrong, because you don’t know that they are all different. It might be that some of them are different and some of them are the same. The next part gets into that.
\(\blacksquare\)
- Why might you now want to run some kind of follow-up test? Run the appropriate thing and explain briefly what you conclude from it, in the context of the data.
Solution
The overall Mood test is significant, so there are some differences between the education groups, but we don’t know where they are. Pairwise median tests will reveal where any differences are:
pairwise_median_test(gss, tvhours, degree)The people whose education is high school or less are significantly different from the other two education levels. The boxplot reveals that this is because they watch more TV on average. The college and graduate groups are not significantly different (in median TV watching).
Extra 1:
You might have been surprised that the College and Graduate medians were not significantly different. After all, they look quite different on the boxplot. Indeed, the P-value for comparing just those two groups is 0.0512, only just over 0.05. But remember that we are doing three tests at once, so the Bonferroni adjustment is to multiply the P-values by 3, so this P-value is “really” some way from being significant. I thought I would investigate this in more detail:
gss %>% filter(degree != "HSorLess") %>%
median_test(tvhours, degree)$grand_median
[1] 2
$table
above
group above below
College 67 70
Graduate 18 36
$test
what value
1 statistic 3.8027625
2 df 1.0000000
3 P-value 0.0511681The College group are about 50-50 above and below the overall median, but the Graduate group are two-thirds below. This suggests that the Graduate group watches less TV, and with these sample sizes I would have expected a smaller P-value. But it didn’t come out that way.
You might also be concerned that there are in total more values below the grand median (106) than above (only 85). This must mean that there are a lot of data values equal to the grand median:
gss %>% filter(degree != "HSorLess") -> gss1
gss1 %>% summarize(med=median(tvhours))and
gss1 %>% count(tvhours)Everybody gave a whole number of hours, and there are not too many different ones; in addition, a lot of them are equal to the grand median of 2.
Extra 2:
Regular ANOVA and Welch ANOVA should be non-starters here because of the non-normality, but you might be curious about how they would perform:
gss.1 <- aov(tvhours~degree, data=gss)
summary(gss.1) Df Sum Sq Mean Sq F value Pr(>F)
degree 2 267 133.30 25.18 2.27e-11 ***
Residuals 902 4774 5.29
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1TukeyHSD(gss.1) Tukey multiple comparisons of means
95% family-wise confidence level
Fit: aov(formula = tvhours ~ degree, data = gss)
$degree
diff lwr upr p adj
Graduate-College -0.4238095 -1.1763372 0.3287181 0.3831942
HSorLess-College 1.0598958 0.6181202 1.5016715 0.0000001
HSorLess-Graduate 1.4837054 0.8037882 2.1636225 0.0000011and
oneway.test(tvhours~degree, data=gss)
One-way analysis of means (not assuming equal variances)
data: tvhours and degree
F = 37.899, num df = 2.00, denom df = 206.22, p-value = 9.608e-15gamesHowellTest(tvhours~factor(degree), data=gss)
Pairwise comparisons using Games-Howell testdata: tvhours by factor(degree) College Graduate
Graduate 0.12 -
HSorLess 2.4e-10 1.7e-10
P value adjustment method: nonealternative hypothesis: two.sidedThe conclusions are actually identical to our Mood test, and the P-values are actually not all that much different. Which makes me wonder just how bad the sampling distributions of the sample means are. Bootstrap to the rescue:
gss %>%
nest_by(degree) %>%
mutate(sim = list(1:1000)) %>%
unnest(sim) %>%
rowwise() %>%
mutate(my_sample = list(sample(data$tvhours, replace = TRUE))) %>%
mutate(my_mean = mean(my_sample)) %>%
ggplot(aes(x = my_mean)) + geom_histogram(bins = 12) +
facet_wrap(~degree, scales = "free")
Coding this made my head hurt, but building it one line at a time, I pretty much got it right first time. In words:
- “compress” the dataframe to get one row per degree and a list-column called
datawith the number of hours of TV watched for each person with thatdegree - generate 1000
sims for eachdegree(to guide the taking of bootstrap samples shortly) - organize into one row per
sim - then take bootstrap samples as normal and work out the mean of each one
- make histograms for each
degree, using a different scale for each one. (This has the advantage that the normal number ofbinswill work for all the histograms.)
If you are not sure about what happened, run it one line at a time and see what the results look like after each one.
Anyway, even though the data was very much not normal, these sampling distributions are very normal-looking, suggesting that something like Welch ANOVA would have been not nearly as bad as you would have guessed. This is evidently because of the big sample sizes. (This also explains why the two other flavours of ANOVA gave results very similar to Mood’s median test.)
\(\blacksquare\)
13.17 Death of poets
Some people believe that poets, especially female poets, die younger than other types of writer. William Butler Yeats15 wrote:
She is the Gaelic16 muse, for she gives inspiration to those she persecutes. The Gaelic poets die young, for she is restless, and will not let them remain long on earth.
A literature student wanted to investigate this, and so collected a sample of 123 female writers (of three different types), and noted the age at death of each writer.
The data are in http://ritsokiguess.site/datafiles/writers.csv.
- Read in and display (some of) the data.
Solution
The usual:
my_url <- "http://ritsokiguess.site/datafiles/writers.csv"
writers <- read_csv(my_url)Rows: 123 Columns: 3
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (1): Type
dbl (2): Type1, Age
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.writersThere are indeed 123 writers. The second column shows the principal type of writing each writer did, and the third column shows their age at death. The first column is a numerical code for the type of writing, which we ignore (since we can handle the text writing type).
\(\blacksquare\)
- Make a suitable plot of the ages and types of writing.
Solution
As usual, one quantitative and one categorical, so a boxplot:
ggplot(writers, aes(x=Type, y=Age)) + geom_boxplot()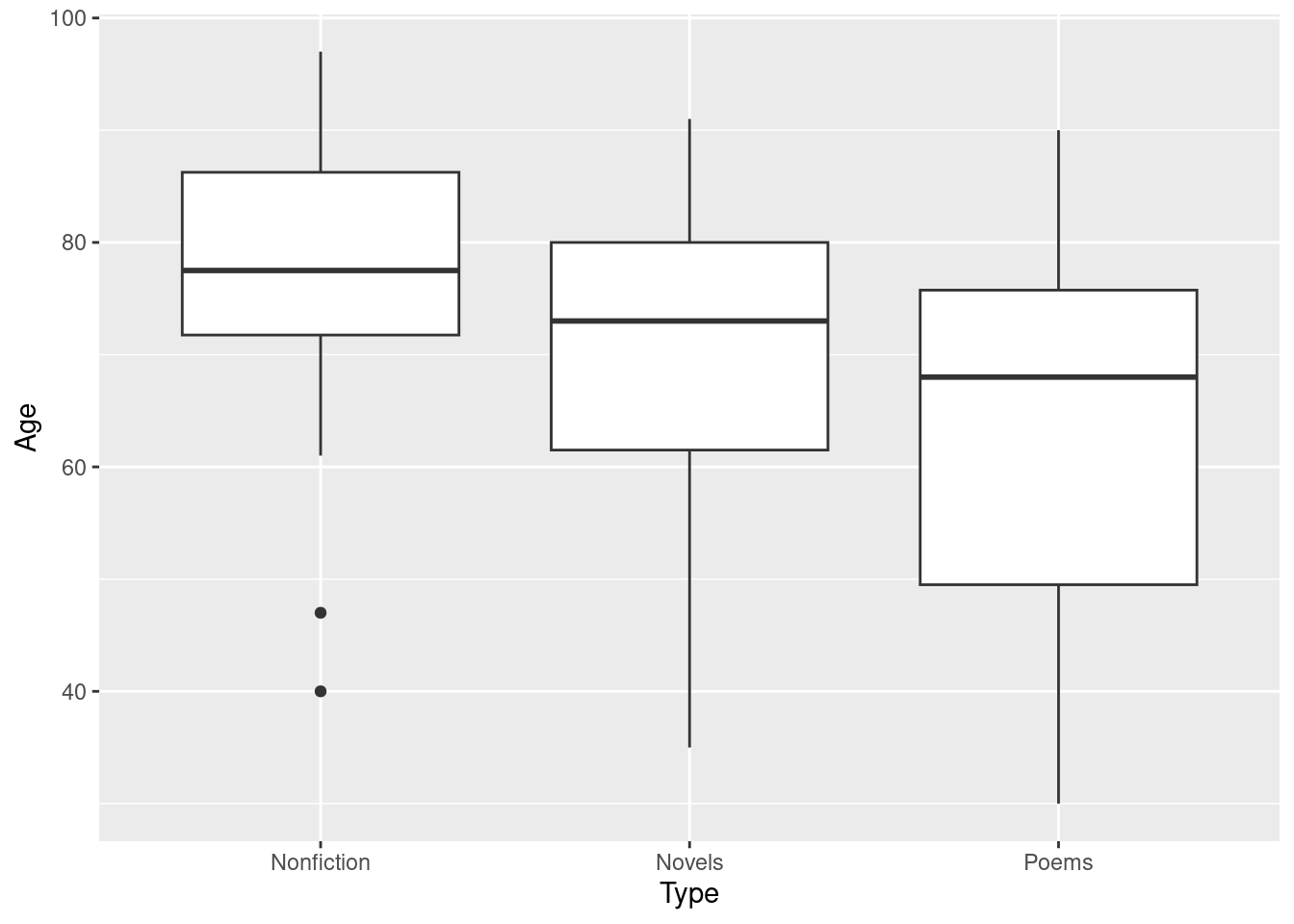
At this point, a boxplot is best, since right now you are mostly after a general sense of what is going on, rather than assessing normality in particular (that will come later).
\(\blacksquare\)
- Obtain a summary table showing, for each type of writing, the number of writers of that type, along with the mean, median and standard deviation of their ages at death.
Solution
The customary group_by and summarize:
writers %>% group_by(Type) %>%
summarize(n=n(), mean=mean(Age), med=median(Age), sd=sd(Age))\(\blacksquare\)
- Run a complete analysis, starting with an ordinary (not Welch) analysis of variance, that ends with a conclusion in the context of the data and an assessment of assumptions.
Solution
I’ve left this fairly open-ended, to see how well you know what needs to be included and what it means. There is a lot of room here for explanatory text to show that you know what you are doing. One output followed by another without any explanatory text suggests that you are just copying what I did without any idea about why you are doing it.
The place to start is the ordinary (not Welch) ANOVA. You may not think that this is the best thing to do (you’ll have a chance to talk about that later), but I wanted to make sure that you practiced the procedure:
writers.1 <- aov(Age~Type, data=writers)
summary(writers.1) Df Sum Sq Mean Sq F value Pr(>F)
Type 2 2744 1372.1 6.563 0.00197 **
Residuals 120 25088 209.1
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1This says that the mean ages at death of the three groups of writers are not all the same, or that there are differences among those writers (in terms of mean age at death). “The mean ages of the types of writer are different” is not accurate enough, because it comes too close to saying that all three groups are different, which is more than you can say right now.
The \(F\)-test is significant, meaning that there are some differences among17 the means, and Tukey’s method will enable us to see which ones differ:
TukeyHSD(writers.1) Tukey multiple comparisons of means
95% family-wise confidence level
Fit: aov(formula = Age ~ Type, data = writers)
$Type
diff lwr upr p adj
Novels-Nonfiction -5.427239 -13.59016 2.735681 0.2591656
Poems-Nonfiction -13.687500 -22.95326 -4.421736 0.0018438
Poems-Novels -8.260261 -15.63375 -0.886772 0.0240459There is a significant difference in mean age at death between the poets and both the other types of writer. The novelists and the nonfiction writers do not differ significantly in mean age at death.
We know from the boxplots (or the summary table) that this significant difference was because the poets died younger on average, which is exactly what the literature student was trying to find out. Thus, female poets really do die younger on average than female writers of other types. It is best to bring this point out, since this is the reason we (or the literature student) were doing this analysis in the first place. See Extra 1 for more.
So now we need to assess the assumptions on which the ANOVA depends.
The assumption we made is that the ages at death of the authors of each different type had approximately a normal distribution (given the sample sizes) with approximately equal spread. The boxplots definitely look skewed to the left (well, not the poets so much, but the others definitely). So now consider the sample sizes: 24, 67, and 32 for the three groups (respectively), and make a call about whether you think the normality is good enough. You are certainly entitled to declare the two outliers on the nonfiction writers to be too extreme given a sample size of only 24. Recall that once one sample fails normality, that’s all you need.
Now, since you specifically want normality, you could reasonably look at normal quantile plots instead of the boxplots. Don’t just get normal quantile plots, though; say something about why you want them instead of the boxplots you drew earlier:
ggplot(writers, aes(sample = Age)) +
stat_qq() + stat_qq_line() +
facet_wrap(~Type)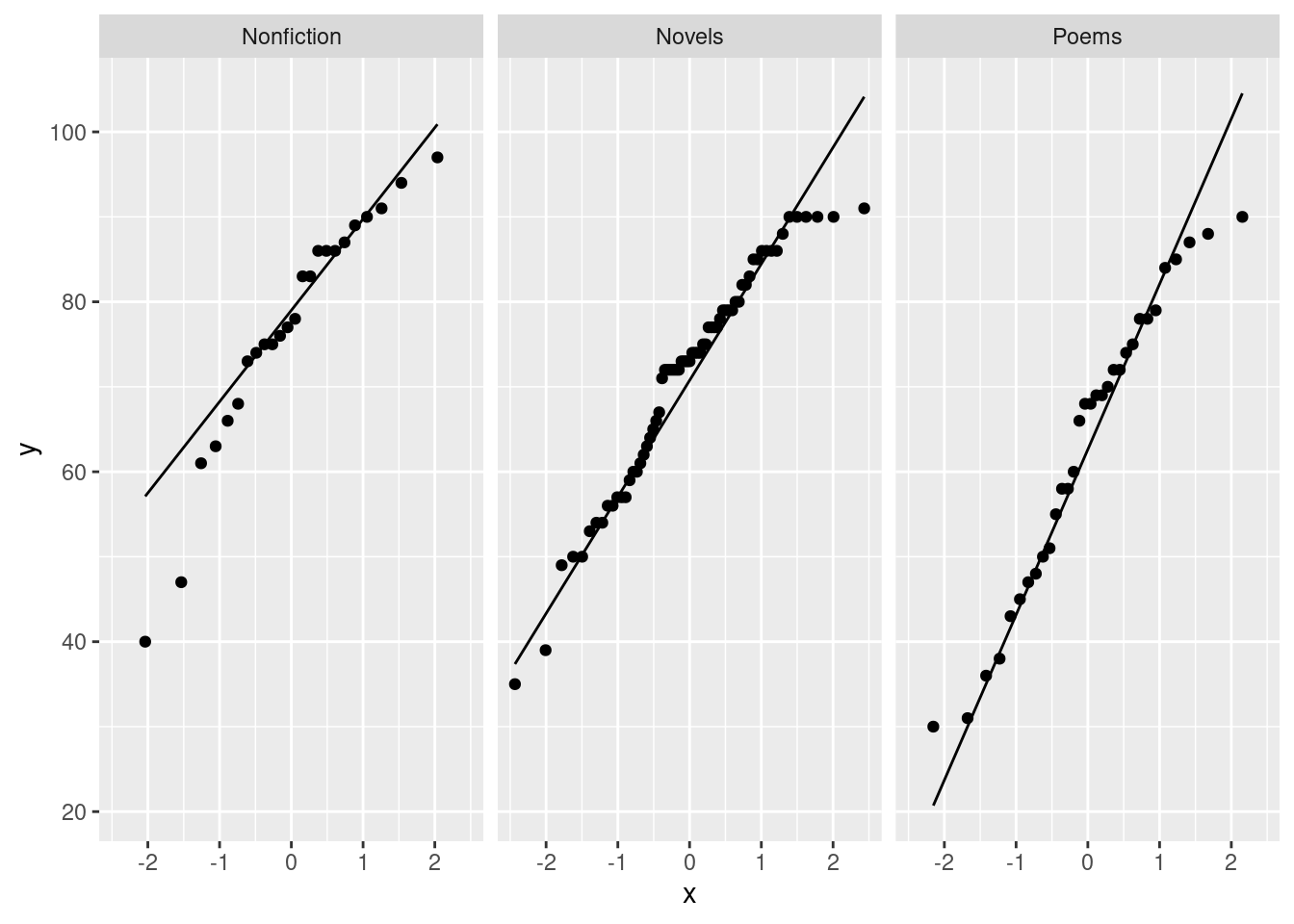
I see that the Nonfiction writers have two outliers at the low end (and are otherwise not bad); the writers of Novels don’t go up high enough (it’s almost as if there is some magic that stops them living beyond 90!); the writers of Poems have a short-tailed distribution. You’ll remember that short tails are not a problem, since the mean is still descriptive of such a distribution; it’s long tails or outliers or skewness that you need to be worried about. The outliers in the Nonfiction writers are the biggest concern.
Are you concerned that these outliers are a problem, given the sample size? There are only 24 nonfiction writers (from your table of means earlier), so the Central Limit Theorem will help a bit. Make a call about whether these outliers are a big enough problem. You can go either way on this, as long as you raise the relevant issues.
Another approach you might take is to look at the P-values. The one in the \(F\)-test is really small, and so is one of the ones in the Tukey. So even if you think the analysis is a bit off, those conclusions are not likely to change. The 0.02 P-value in the Tukey, however, is another story. This could become non-significant in actual fact if the P-value is not to be trusted.
Yet another approach (looking at the bootstrapped sampling distributions of the sample means) is in Extra 3. This gets more than a little hairy with three groups, especially doing it the way I do.
If you think that the normality is not good enough, it’s a good idea to suggest that we might do a Mood’s Median Test instead, and you could even do it (followed up with pairwise median tests). If you think that normality is all right, you might then look at the spreads. I think you ought to conclude that these are close enough to equal (the SDs from the summary table or the heights of the boxes on the boxplots), and so there is no need to do a Welch ANOVA. (Disagree if you like, but be prepared to make the case.)
I have several Extras:
Extra 1: having come to that tidy conclusion, we really ought to back off a bit. These writers were (we assume) a random sample of some population, but they were actually mostly Americans, with a few Canadian and Mexican writers. So this appears to be true at least for North American writers. But this is (or might be) a different thing to the Yeats quote about female Gaelic poets.
There is a more prosaic reason. It is harder (in most places, but especially North America) to get poetry published than it is to find a market for other types of writing. (A would-be novelist, say, can be a journalist or write for magazines to pay the bills while they try to find a publisher for their novel.) Thus a poet is living a more precarious existence, and that might bring about health problems.
Extra 2: with the non-normality in mind, maybe Mood’s median test is the thing:
median_test(writers, Age, Type)$grand_median
[1] 73
$table
above
group above below
Nonfiction 17 6
Novels 33 30
Poems 10 22
$test
what value
1 statistic 9.872664561
2 df 2.000000000
3 P-value 0.007180888The P-value here is a bit bigger than for the \(F\)-test, but it is still clearly significant. Hence, we do the pairwise median tests to find out which medians differ:
pairwise_median_test(writers, Age, Type)The conclusion here is exactly the same as for the ANOVA. The P-values have moved around a bit, though: the first one is a little closer to significance (remember, look at the last column since we are doing three tests at once) and the last one is now only just significant.
writers %>% group_by(Type) %>%
summarize(n=n(), mean=mean(Age), med=median(Age), sd=sd(Age))In both of these two cases (Nonfiction-Novels and Novels-Poems), the medians are closer together than the means are. That would explain why the Novels-Poems P-value would increase, but not why the Nonfiction-Novels one would decrease.
I would have no objection in general to your running a Mood’s Median Test on these data, but the point of this problem was to give you practice with aov.
Extra 3: the other way to assess if the normality is OK given the sample sizes is to obtain bootstrap sampling distributions of the sample means for each Type. The sample size for the novelists is 67, so I would expect the skewness there to be fine, but the two outliers among the Nonfiction writers may be cause for concern, since there are only 24 of those altogether.
Let’s see if we can do all three at once (I like living on the edge). I take things one step at a time, building up a pipeline as I go. Here’s how it starts:
writers %>% nest_by(Type)The thing data is a so-called list-column. The dataframes we have mostly seen so far are like spreadsheets, in that each “cell” or “entry” in a dataframe has something like a number or a piece of text in it (or, occasionally, a thing that is True or False, or a date). Tibble-type dataframes are more flexible than that, however: each cell of a dataframe could contain anything.
In this one, the three things in the column data are each dataframes,18 containing the column called Age from the original dataframe. These are the ages at death of the writers of that particular Type. These are the things we want bootstrap samples of.
I’m not at all sure how this is going to go, so let’s shoot for just 5 bootstrap samples to start with. If we can get it working, we can scale up the number of samples later, but having a smaller number of samples is easier to look at:
writers %>% nest_by(Type) %>%
mutate(sim = list(1:5))Let me break off at this point to say that we want 1000 bootstrap samples for the writers of each type, so this is the kind of thing we need to start with. nest_by has an implied rowwise, so we get three lots of values in sim; the list is needed since each one is five values rather than just one. The next stage is to unnest these, and then do another rowwise to work with all the (more) rows of the dataframe we now have. After that, the process should look more or less familiar:
writers %>% nest_by(Type) %>%
mutate(sim = list(1:5)) %>%
unnest(sim) %>%
rowwise() %>%
mutate(my_sample = list(sample(data$Age, replace = TRUE)))That seems to be about the right thing; the bootstrap samples appear to be the right size, considering how many writers of each type our dataset had. From here, work out the mean of each sample:
writers %>% nest_by(Type) %>%
mutate(sim = list(1:5)) %>%
unnest(sim) %>%
rowwise() %>%
mutate(my_sample = list(sample(data$Age, replace = TRUE))) %>%
mutate(my_mean = mean(my_sample))and then you could plot those means. This seems to be working, so let’s scale up to 1000 simulations, and make normal quantile plots of the bootstrapped sampling distributions, one for each Type of writer:
writers %>% nest_by(Type) %>%
mutate(sim = list(1:1000)) %>%
unnest(sim) %>%
rowwise() %>%
mutate(my_sample = list(sample(data$Age, replace = TRUE))) %>%
mutate(my_mean = mean(my_sample)) %>%
ggplot(aes(sample = my_mean)) + stat_qq() +
stat_qq_line() + facet_wrap(~Type, scales = "free")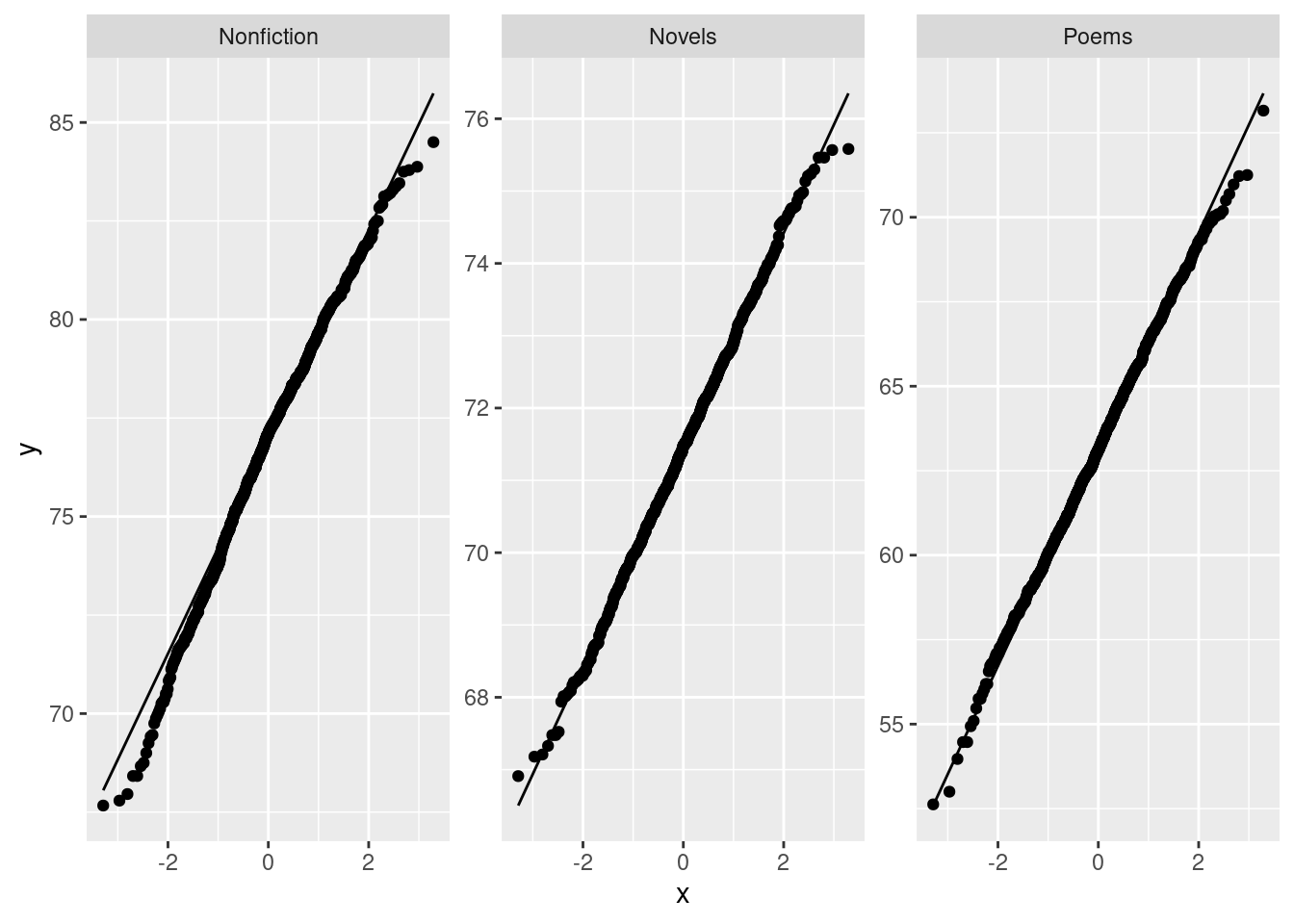
These three normal quantile plots are all acceptable, to my mind, although the Nonfiction one, with the two outliers and the smallest sample size, is still a tiny bit skewed to the left. Apart from that, the three sampling distributions of the sample means are close to normal, so our aov is much better than you might have thought from looking at the boxplots. That’s the result of having large enough samples to get help from the Central Limit Theorem.
\(\blacksquare\)
13.18 Religion and studying
Many students at a certain university were asked about the importance of religion in their lives (categorized as “not”, “fairly”, or “very” important), and also about the number of hours they spent studying per week. (This was part of a much larger survey.) We want to see whether there is any kind of relationship between these two variables. The data are in here.
- Read in and display (some of) the data.
Solution
The usual. This is a straightforward one:
my_url <- "http://ritsokiguess.site/datafiles/student_relig.csv"
student <- read_csv(my_url)Rows: 686 Columns: 2
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (1): ReligImp
dbl (1): StudyHrs
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.student686 students, with columns obviously named for religious importance and study hours.
Extra:
I said this came from a bigger survey, actually this one:
my_url <- "http://ritsokiguess.site/datafiles/student0405.csv"
student0 <- read_csv(my_url)Rows: 690 Columns: 7
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (3): Sex, ReligImp, Seat
dbl (4): GPA, MissClass, PartyDays, StudyHrs
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.student0There are four extra rows here. Why? Let’s look at a summary of the dataframe:
summary(student0) Sex GPA ReligImp MissClass
Length:690 Min. :1.500 Length:690 Min. :0.0000
Class :character 1st Qu.:2.930 Class :character 1st Qu.:0.0000
Mode :character Median :3.200 Mode :character Median :1.0000
Mean :3.179 Mean :0.9064
3rd Qu.:3.515 3rd Qu.:1.0000
Max. :4.000 Max. :6.0000
NA's :3 NA's :1
Seat PartyDays StudyHrs
Length:690 Min. : 0.000 Min. : 0.00
Class :character 1st Qu.: 3.000 1st Qu.: 6.25
Mode :character Median : 7.000 Median :10.00
Mean : 7.501 Mean :13.16
3rd Qu.:11.000 3rd Qu.:16.00
Max. :31.000 Max. :70.00
NA's :4 You get information about each variable. For the text variables, you don’t learn much, only how many there are. (See later for more on this.) For each of the four quantitative variables, you see some stats about each one, along with a count of missing values. The study hours variable is evidently skewed to the right (mean bigger than median), which we will have to think about later.
R also has a “factor” variable type, which is the “official” way to handle categorical variables in R. Sometimes it matters, but most of the time leaving categorical variables as text is just fine. summary handles these differently. My second line of code below says “for each variable that is text, make it into a factor”:
student0 %>%
mutate(across(where(is.character), ~factor(.))) %>%
summary() Sex GPA ReligImp MissClass Seat
Female:382 Min. :1.500 Fairly:319 Min. :0.0000 Back :134
Male :308 1st Qu.:2.930 Not :222 1st Qu.:0.0000 Front :151
Median :3.200 Very :149 Median :1.0000 Middle:404
Mean :3.179 Mean :0.9064 NA's : 1
3rd Qu.:3.515 3rd Qu.:1.0000
Max. :4.000 Max. :6.0000
NA's :3 NA's :1
PartyDays StudyHrs
Min. : 0.000 Min. : 0.00
1st Qu.: 3.000 1st Qu.: 6.25
Median : 7.000 Median :10.00
Mean : 7.501 Mean :13.16
3rd Qu.:11.000 3rd Qu.:16.00
Max. :31.000 Max. :70.00
NA's :4 For factors, you also get how many observations there are in each category, and the number of missing values, which we didn’t get before. However, ReligImp does not have any missing values.
I said there were four missing values for study hours, that is, four students who left that blank on their survey. We want to get rid of those students (that is, remove those whole rows), and, to simplify things for you, let’s keep only the study hours and importance of religion columns. That goes like this:
student0 %>% drop_na(StudyHrs) %>%
select(ReligImp, StudyHrs)Then I saved that for you. 686 rows instead of 690, having removed the four rows with missing StudyHrs.
Another (better, but more complicated) option is to use the package pointblank, which produces much more detailed data validation reports. You would start that by piping your data into scan_data() to get a (very) detailed report of missingness and data values, and then you can check your data for particular problems, such as missing values, or values bigger or smaller than they should be, for the variables you care about. See here for more.
\(\blacksquare\)
- Obtain the number of observations and the mean and standard deviation of study hours for each level of importance.
Solution
group_by and summarize (spelling the latter with s or z as you prefer):
student %>% group_by(ReligImp) %>%
summarize(n=n(), mean_sh=mean(StudyHrs), sd_sh=sd(StudyHrs))\(\blacksquare\)
- Comment briefly on how the groups compare in terms of study hours.
Solution
The students who think religion is very important have a higher mean number of study hours. The other two groups seem similar.
As far as the SDs are concerned, make a call. You could say that the very-important group also has a (slightly) larger SD, or you could say that the SDs are all very similar.
I would actually favour the second one, but this is going to be a question about Welch ANOVA, so go whichever way you like.
\(\blacksquare\)
- Make a suitable graph of this data set.
Solution
This kind of data is one quantitative and one categorical variable, so once again a boxplot:
ggplot(student, aes(x=ReligImp, y=StudyHrs)) + geom_boxplot()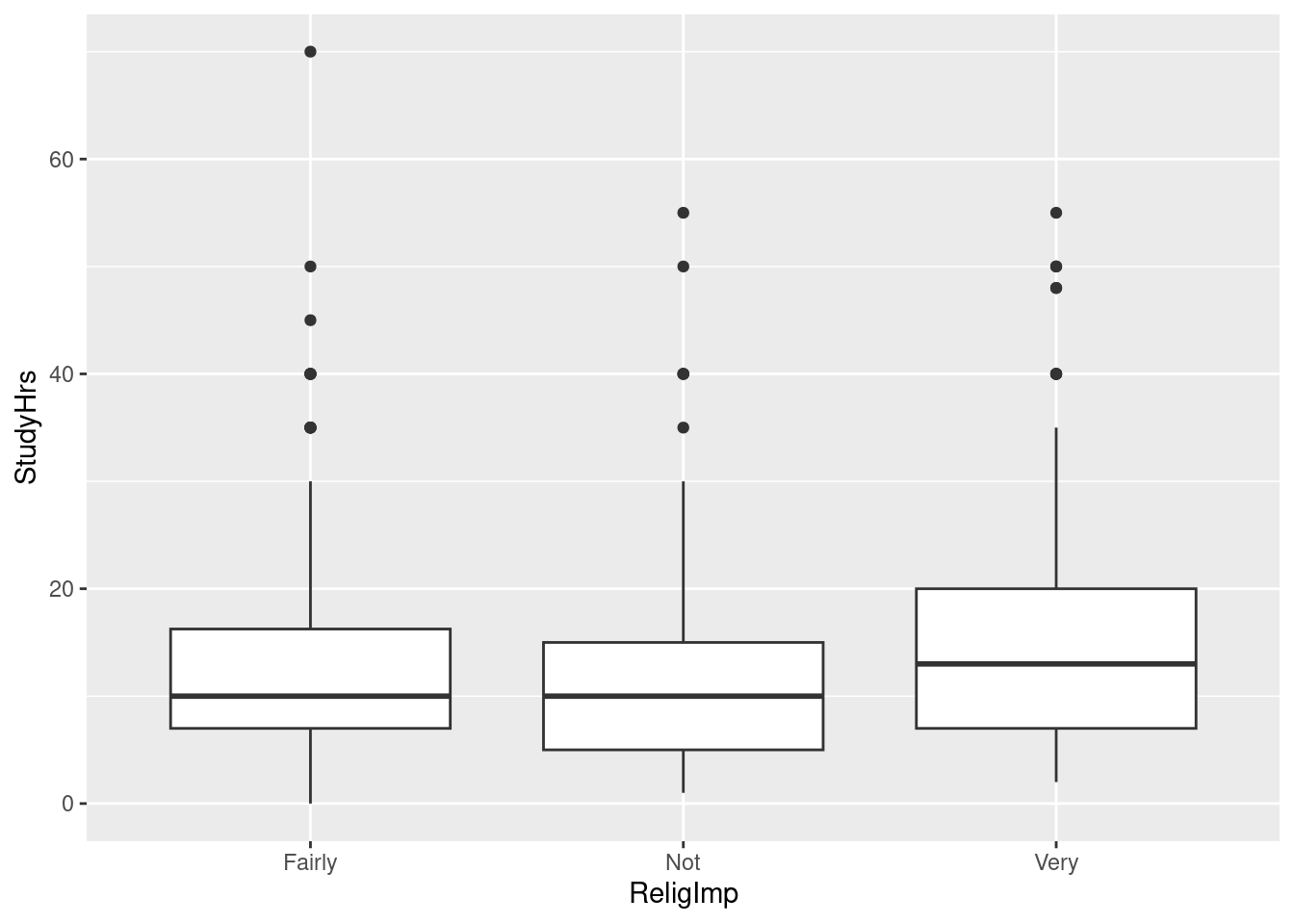
\(\blacksquare\)
- The statistician in this study decided that the data were sufficiently normal in shape given the (very large) sample sizes, but was concerned about unequal spreads among the three groups. Given this, run a suitable analysis and display the output. (This includes a suitable follow-up test, if warranted.)
Solution
Normal-enough data (in the statistician’s estimation) and unequal spreads means a Welch ANOVA:
oneway.test(StudyHrs~ReligImp, data=student)
One-way analysis of means (not assuming equal variances)
data: StudyHrs and ReligImp
F = 7.9259, num df = 2.0, denom df = 350.4, p-value = 0.0004299gamesHowellTest(StudyHrs~factor(ReligImp), data=student)
Pairwise comparisons using Games-Howell testdata: StudyHrs by factor(ReligImp) Fairly Not
Not 0.26035 -
Very 0.00906 0.00026
P value adjustment method: nonealternative hypothesis: two.sidedGames-Howell is the suitable follow-up here, to go with the Welch ANOVA. It is warranted because the Welch ANOVA was significant.
Make sure you have installed and loaded PMCMRplus before trying the second half of this.
Extra: for large data sets, boxplots make it look as if the outlier problem is bad, because a boxplot of a large amount of data will almost certainly contain some outliers (according to Tukey’s definition). Tukey envisaged a boxplot as something you could draw by hand for a smallish data set, and couldn’t foresee something like R and the kind of data we might be able to deal with. To show you the kind of thing I mean, let’s draw some random samples of varying sizes from normal distributions, which should not have outliers, and see how their boxplots look:
tibble(n=c(10, 30, 100, 300)) %>%
rowwise() %>%
mutate(my_sample = list(rnorm(n))) %>%
unnest(my_sample) %>%
ggplot(aes(x = factor(n), y = my_sample)) + geom_boxplot()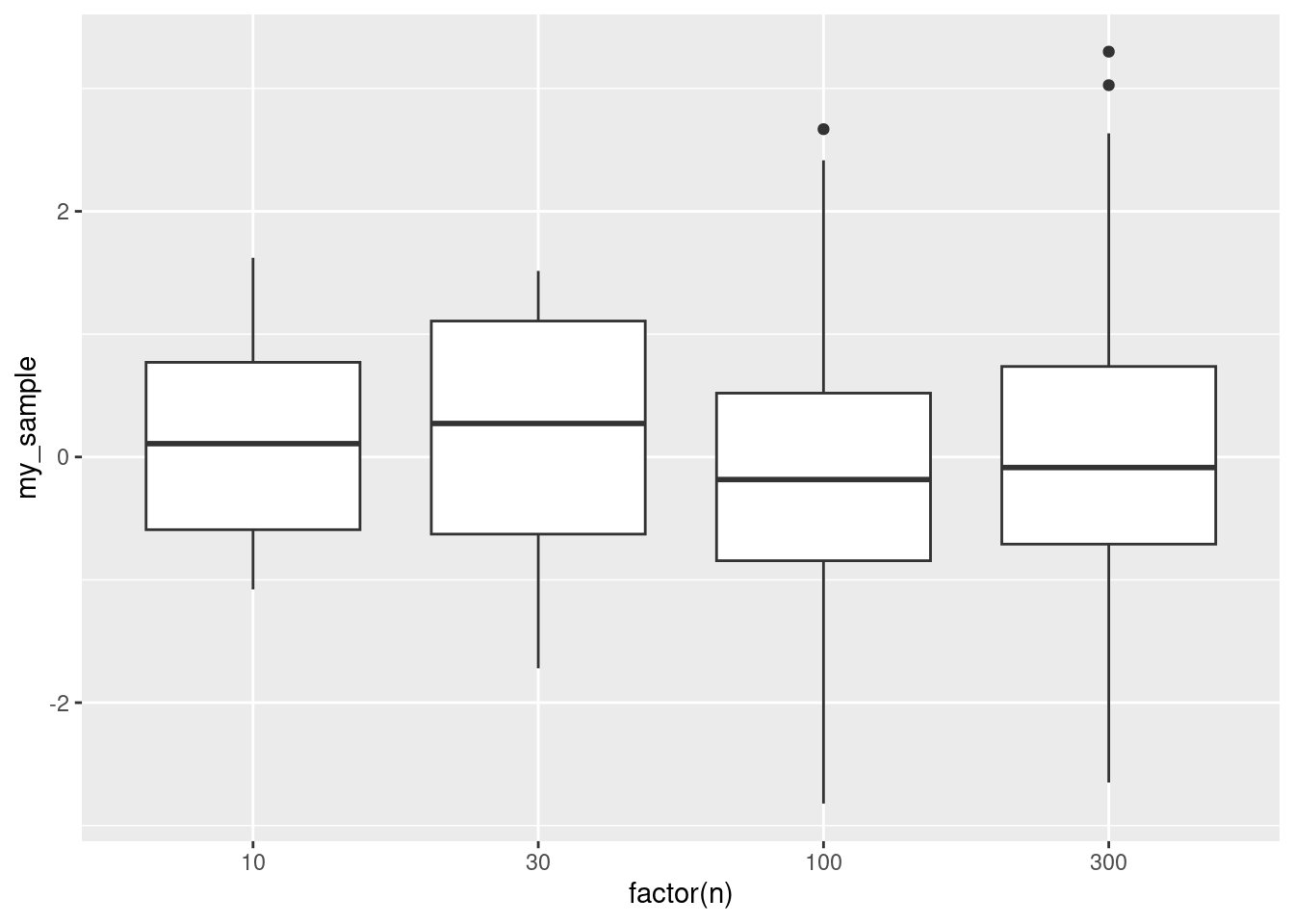
As the sample size gets bigger, the number of outliers gets bigger, and the whiskers get longer. All this means is that in a larger sample, you are more likely to see a small number of values that are further out, and that is not necessarily a reason for concern. Here, the outliers are only one value out of 100 and two out of 300, but they have what looks like an outsize influence on the plot. In the boxplot for our data, the distributions were a bit skewed, but the outliers may not have been as much of a problem as they looked.
\(\blacksquare\)
- What do you conclude from your analysis of the previous part, in the context of the data?
Solution
The Welch ANOVA was significant, so the religious-importance groups are not all the same in terms of mean study hours, and we need to figure out which groups differ from which. (Or say this in the previous part if you wish.)
The students for whom religion was very important had a significantly different mean number of study hours than the other students; the Fairly and Not groups were not significantly different from each other. Looking back at the means (or the boxplots), the significance was because the Very group studied for more hours than the other groups. It seems that religion has to be very important to a student to positively affect how much they study.
Extra: you might have been concerned that the study hours within the groups were not nearly normal enough to trust the Welch ANOVA. But the groups were large, so there is a lot of help from the Central Limit Theorem. Enough? Well, that is hard to judge.
My take on this is to bootstrap the sampling distribution of the sample mean for each group. If that looks normal, then we ought to be able to trust the \(F\)-test (regular or Welch, as appropriate). The code is complicated (I’ll explain the ideas below):
student %>%
nest_by(ReligImp) %>%
mutate(sim = list(1:1000)) %>%
unnest(sim) %>%
rowwise() %>%
mutate(my_sample = list(sample(data$StudyHrs, replace = TRUE))) %>%
mutate(my_mean = mean(my_sample)) %>%
ggplot(aes(sample = my_mean)) + stat_qq() + stat_qq_line() +
facet_wrap(~ReligImp, scales = "free")
To truly understand what’s going on, you probably need to run this code one line at a time.
Anyway, these normal quantile plots are very normal. This says that the sampling distributions of the sample means are very much normal in shape, which means that the sample sizes are definitely large enough to overcome the apparently bad skewness that we saw on the boxplots. In other words, using a regular or Welch ANOVA will be perfectly good; there is no need to reach for Mood’s median test here, despite what you might think from looking at the boxplots, because the sample sizes are so large.
The code, line by line:
- create mini-data-frames called
data, containing one column calledStudyHrs, for eachReligImpgroup - set up for 1000 bootstrap samples for each group, and (next line) arrange for one row per bootstrap sample
- work rowwise
- generate the bootstrap samples
- work out the mean of each bootstrap sample
- plot normal quantile plots of them, using different facets for each group.
Finally, you might have wondered whether we needed to do Welch:
student.1 <- aov(StudyHrs~ReligImp, data=student)
summary(student.1) Df Sum Sq Mean Sq F value Pr(>F)
ReligImp 2 1721 860.7 9.768 6.57e-05 ***
Residuals 683 60184 88.1
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1TukeyHSD(student.1) Tukey multiple comparisons of means
95% family-wise confidence level
Fit: aov(formula = StudyHrs ~ ReligImp, data = student)
$ReligImp
diff lwr upr p adj
Not-Fairly -1.195917 -3.1267811 0.7349462 0.3135501
Very-Fairly 3.143047 0.9468809 5.3392122 0.0023566
Very-Not 4.338964 1.9991894 6.6787385 0.0000454It didn’t make much difference, and the conclusions are identical. So I think either way would have been defensible.
The value of doing Tukey is that we get confidence intervals for the difference of means between each group, and this gives us an “effect size”: the students for whom religion was very important studied on average three or four hours per week more than the other students, and you can look at the confidence intervals to see how much uncertainty there is in those estimates. Students vary a lot in how much they study, but the sample sizes are large, so the intervals are not that long.
\(\blacksquare\)
An Irish, that is to say, Gaelic, poet (see below), but a male one.↩︎
Gaelic is a language of Scotland and Ireland, and the culture of the people who speak it.↩︎
Actually, this doesn’t always work if the sample sizes in each group are different. If you’re comparing two small groups, it takes a very large difference in means to get a small P-value. But in this case the sample sizes are all the same.↩︎
The computer scientists among you will note that I should not use equals or not-equals to compare a decimal floating-point number, since decimal numbers are not represented exactly in the computer. R, however, is ahead of us here, since when you try to do “food not equal to 4.7”, it tests whether food is more than a small distance away from 4.7, which is the right way to do it. In R, therefore, code like my
food != 4.7does exactly what I want, but in a language like C, it does not, and you have to be more careful:abs(food-4.7)>1e-8, or something like that. The small number1e-8(\(10^{-8}\)) is typically equal to machine epsilon, the smallest number on a computer that is distinguishable from zero.↩︎Most of these parts are old from assignment questions that I actually asked a previous class to do, but not this part. I added it later.↩︎
See discussion elsewhere about Yates’ Correction and fixed margins.↩︎
In the pairwise median test in
smmr, I did this backwards: rather than changing the alpha that you compare each P-value with from 0.05 to 0.05/6, I flip it around so that you adjust the P-values by multiplying them by 6, and then comparing the adjusted P-values with the usual 0.05. It comes to the same place in the end, except that this way you can get adjusted P-values that are greater than 1, which makes no sense. You read those as being definitely not significant.↩︎It’s probably better in a report to use language a bit more formal than a bunch. Something like a number would be better.↩︎
The use of absolute differences, and the median, downplays the influence of outliers. The assumption here is that the absolute differences from the medians are approximately normal, which seems a less big assumption than assuming the actual data are approximately normal.↩︎
This is coming back to the power of something like Levene’s test; the power of any test is not going to be very big if the sample sizes are small.↩︎
The test goes back to the 1940s.↩︎
Best, D. J., and J. C. W. Rayner. “Welch’s Approximate Solution for the Behrens–Fisher Problem.” Technometrics 29, no. 2 (May 1, 1987): 205–10. doi:10.1080/00401706.1987.10488211. The data set is near the end.↩︎
We’d need a lot more students to make it narrower, but this is not surprising since students vary in a lot of other ways that were not measured here.↩︎
Perhaps a better word here would be principle, to convey the idea that you can do something else if it works better for your purposes.↩︎
An Irish, that is to say, Gaelic, poet (see below), but a male one.↩︎
Gaelic is a language of Scotland and Ireland, and the culture of the people who speak it.↩︎
There might be differences between two things, but among three or more.↩︎
Like those Russian dolls.↩︎